The music in a toy commercial isn’t just background noise. It tells you who the advert is for, and a machine learning model can hear it (even when you barely notice the difference). Luca Marinellitells us more.
Next time you’re watching TV, try muting the adverts and then turning the sound back on. You’ll probably notice something odd. The music in adverts for dolls and playsets sounds completely different from the music in adverts for action figures and toy cars. One sounds smooth and tuneful. The other sounds loud and chaotic. But here’s the question: is that just your imagination, or is the difference real and measurable? For my PhD research at Queen Mary University of London I decided to find out using machine learning.
I collected over 600 toy commercials from a UK retailer’s YouTube channel, split into three groups: ads aimed at girls, ads aimed at boys, and ads aimed at mixed audiences. Then I fed the soundtracks into a computer program and had it extract dozens of measurements from each one. Not “does this sound nice?” (computers can’t answer that) but more precise numerical values like “how rough does the sound spectrum look”, “how regular is the beat” or “how clearly does this audio sit in a musical key”. Think of it as turning every piece of music into a long list of numbers that each describe a property of it.
Then I trained a type of machine learning model called a classifier, to look at those numbers and predict: is this intended as a girls’ ad, a boys’ ad, or a mixed one? The classifier got it right a remarkable 91% of the time when comparing girls-only and boys-only ads. That’s not luck. That’s a genuine, detectable pattern hidden in the sound. But which measurements were actually doing the work? This is where the research gets interesting, and where a technique called SHAP (Shapley Additive exPlanations) comes in. SHAP is a way of asking a machine learning model to explain its own decisions. Instead of just getting a yes/no answer, you can ask: “which features pushed you towards saying this was a girls’ ad, and which ones pushed you the other way?” It’s a bit like asking a judge not just for a verdict, but for their full reasoning.
What SHAP revealed was striking. Ads targeting girls consistently had higher harmonicity, meaning the sounds fit together into clear, pleasant musical patterns, and more rhythmic regularity, meaning the beat was steady and predictable. Their audio spectrum (a kind of fingerprint of all the frequencies present) was also broader and smoother. Boys’ ads, by contrast, scored higher on spectral roughness (sounds that are abrasive) and spectral entropy (a measure of how chaotic or unpredictable the sound is). They were also simply louder. In plain terms: girls’ ads sound harmonious and organised. Boys’ ads sound noisy, aggressive, and jagged. And a machine learning model can tell the difference with 91% accuracy just from the audio alone, without seeing a single frame of video. These patterns almost certainly aren’t accidental. Marketers are making deliberate choices about music to signal who a product is “for”. The sound itself carries a hidden message.
We showed how AI can be used to hold up a mirror to human behaviour. When we use explainable AI we can spot patterns in the world that are so familiar we’ve stopped noticing them. The music in a toy advert might seem trivial, but if an algorithm can reliably predict the intended audience just from the soundtrack, that tells us something important: gender stereotypes aren’t just visible, they’re audible too.
Can a machine learn from its mistakes, until it plays a game perfectly, just by following rules? Donald Michie worked out a way in the 1960s. He made a machine out of matchboxes and beads called MENACE that did just that. Our version plays the game Ladder and is made of cups and sweets. Punish the machine when it loses by eating its sweets!
Let’s play the game, Ladder. It is played on a board like a ladder with a single piece (an X) placed on the bottom rung of the ladder. Players take it in turns to make a move, either 1, 2 or 3 places up the ladder. You win if you move the piece to the top of the ladder, so reach the target. We will play on a ladder with 10 rungs as on the right (but you can play on larger ladders).
To make the learning machine, you need 9 plastic cups and lots of wrapped sweets coloured red, green and purple. Spread out the sheets showing the possible board positions (see below) and place a cup on each. Put coloured sweets in each cup to match the arrows: for most positions there are red, green and purple arrows, so you put a red, green and purple sweet in those cups. Once all cups have sweets matching the arrows, your machine is ready to play (and learn).
The machine plays first. Each cup sits on a possible board position that your machine could end up in. Find the cup that matches the board position the game is in when it is its go. Shut your eyes and take a sweet at random from that cup, placing it next to the cup. Make the move indicated by the arrow of that colour. Then the machine’s human opponent makes a move. Once they have moved the machine plays in the same way again, finding the position and taking a sweet to decide its move. Keep playing alternately like this until someone wins. If the machine ends up in a position with no sweets in that cup, then it resigns.
The 9 board positions with arrows showing possible moves. Place a cup on each board position with sweets corresponding to the arrows. Image by Paul Curzon
If the machine loses, then eat the sweet corresponding to the last move it made. It will never make that mistake again! Win or lose, put all the other sweets back.
The initial cup for board position 8, with a red and purple sweet. Image by Paul Curzon
Now, play lots of games like that, punishing the machine by eating the sweet of its last move each time it loses. The machine will play badly at first. It’s just making moves at random. The more it loses, the more sweets (losing moves) you eat, so the better it gets. Eventually, it will play perfectly. No one told it how to win – it learnt from its mistakes because you ate its sweets! Gradually the sweets left encode rules of how to win.
Try slightly different rules. At the moment we just punish bad moves. You could reward all the moves that led to it by adding another sweet of the same colour too. Now the machine will be more likely to make those moves again. What other variations of rewards and punishments could you try?
Why not write a program that learns in the same way – but using data values in arrays to represent moves instead of sweets. Not so yummy!
– Paul Curzon, Queen Mary University of London
Subscribe to be notified whenever we publish a new post to the CS4FN blog.
This blog is funded by EPSRC on research agreement EP/W033615/1.
By Przemysław Wałęga, Queen Mary University of London
Logical reasoning and proof, whether done using math notation or informally in your head, is an important tool of computer scientists. The idea of proving, however, is often daunting for beginners and it takes a lot of practice to master this skill. Here we look at a simple puzzle to get you started.
Computer Scientists use logical reasoning and proofs a lot. They can be used to ensure correctness of algorithms. Researchers doing theoretical computer science use proofs all the time, working out theories about computation.
Proving mathematical statements can be very challenging, though. Coming up with a proof often requires making observations about a problem and exploiting a variety of different proof methods. Making sure that the proof is correct, concise, and easy to follow matters too, but that in itself needs skill and a lot of practice. As a result, proving can be seen as a real art of mathematics.
Let’s think about a simple puzzle to show how logical thinking can be used when solving a problem. The puzzle can be solved without knowing any specific maths, so anyone can attempt it, but it will probably look very hard to start with.
Before you start working on it though, let me recommend that first you try to solve it entirely in your mind, that is, with no pen and paper (and definitely no computer!).
The Puzzle
Here is the puzzle, which I heard at a New Year’s party from a friend Marcin:
Mrs. and Mr. Taylor hosted a party and invited four other couples. After the party, everyone gathered in the hallway to say their goodbyes with handshakes. No one shook hands with themselves (of course!) or their partner, and no one shook hands with the same person more than once. Each person kept track of how many people they had shaken hands with. At one point, Mr. Taylor shouted “STOP” and asked everyone to say how many people they had shaken hands with. He received nine different answers.
How many people did Mrs Taylor shake hands with?
I will give you some hints to help solving the puzzle, but first try to solve it on you own, and see how far you get. Maybe you will be solve the puzzle on your own?
Why did I recommend solving the puzzle without pen and paper? Because, our goal is to use logical and critical thinking instead of finding a solution in a “brute force” manner, that is, blindly listing all the possibilities and checking each of them to find a solution to the puzzle. As an example of a brute force way of solving a problem, take a crossword puzzle where you have all but one of the letters of a word. You have no idea what the clue is about, so instead you just try the 26 possible letters for the missing one and see which make a word and then check which that do fit the clue!
Notice that the setting of our puzzle is finite: there are 10 people shaking hands, so the number of ways they shake hands is also finite if bigger than say checking 26 different letters of the crossword problem. That means you could potentially list all the possible ways people might shake hands to solve the puzzle. This is, however, not what we are aiming for. We would like to solve the puzzle by analysing the structure of the problem instead of performing brute force computation.
Also, it is important to realise that often mathematicians solve puzzles (or prove theorems) about situations in which the number of possibilities is infinite so the brute force approach of listing them all is not possible at all. There are also many situations where the brute force approach is applicable in theory, but in practice it would require considering too many cases: so many that even the most powerful computers would not be able to provide us with an answer in our lifetimes.
For our puzzle, you may be tempted to list all possible handshake situations between 10 people. Before you do start listing them, let’s check how much time you would need for that. You have to consider every pair that can be formed from 10 people. A mathematician refers to that as “10 choose 2”, the answer to which is that there are 45 possible pairs among 10 people (the first person pairs with 9 others, the next has 8 others to pair with having been paired with the first already, and so on and 9+8+….+1 = 45). However, 45 is not the number that we are looking for. Each of these pairs can either shake hands or not, and we need to consider all those different possibilities. There are 245 such handshake combinations. How big is this number? The number 210 is 1024, so it is approximately 1000. Hence 240=(210)4 (which is clearly smaller than our 245) is approximately 10004 = 1,000,000,000,000 that is, a trillion. Listing a trillion combinations should sound scary to you. Indeed, if you can be quick enough to write each of the trillion combinations in one second, you will spend 31 688 years. Let’s not try this!
Of course, we can look more closely at the description of the puzzle to decrease the number of combinations. For example, we know that nobody shakes hands with their partner, which will already massively reduce the number. However, let’s try to solve the puzzle without using any external memory aids or computational power. Only our minds.
Can you solve it? A key trick that mathematicians and computer scientists use is to break down problems into simpler problems first (decomposition). You may not be able to solve this puzzle straight away, so instead think about what facts you can deduce about the situation instead.
If you need help, start by considering Hint 1 below. If you are still stuck, maybe Hint 2 will help? Answer these questions and you will be a long way to solving the puzzle.
Hints
Mr. Taylor received nine different answers. What are these answers?
Knowing the numbers above, can you work out who is a partner of whom?
No luck in solving the puzzle? Try to spend some more time before giving up! Then read on. If you managed to solve it you can compare your way of thinking with the full solution below.
Solution
First we will answer Hint 1. We can show that the answers received by Mr. Taylor are 0, 1, 2, 3, 4, 5, 6, 7, and 8. There are 5 couples, meaning that there are 10 people at the party (Mr. and Mrs. Taylor + 4 other couples). Each person can shake hands with at least 0 people and at most 8 other people (since there are 10 people, and they cannot shake hands with themselves or their partner). Since Mr. Taylor received nine different answers from the other 9 people, they need to be 0, 1, 2, 3, 4, 5, 6, 7, and 8. This is an important observation which we will use in the second part of the solution.
Next, we will answer Hint 2. Let’s call P0 the person who answered 0, P1 the person who answered 1, …, P8 the person who answered 8. The person with the highest (or the lowest) number of handshakes is a good one to look at first.
Who is the partner of P8? P8 did not shake hands with themselves and with P0 (as P0 did not shake hands with anybody). So P8 had to shake hands with all the other 8 people. Since no one shakes hands with their partner, it follows that P0 is the partner of P8!
Who is the partner of P7? They did not shake hands with themselves, with P0 and with P1, because we already know that P1 shook hands with P8, and they shook hands with only one person. So the partner of P7 can be either P8, P0, or P1. Since P8 and P0 are partners, P7 needs to be the partner of P1.
Following through with this analysis for P6 and P5, we can show that the following are partners: P8 and P0, P7 and P1, P6 and P2, P5 and P3. The only person among P0, … , P8 who is left without a partner is P4. So P4 needs to be Mrs. Taylor, the partner of Mr. Taylor, the one person left who didn’t give a number.
Consequently, we have also showed that Mr Taylor shook hands with 4 people.
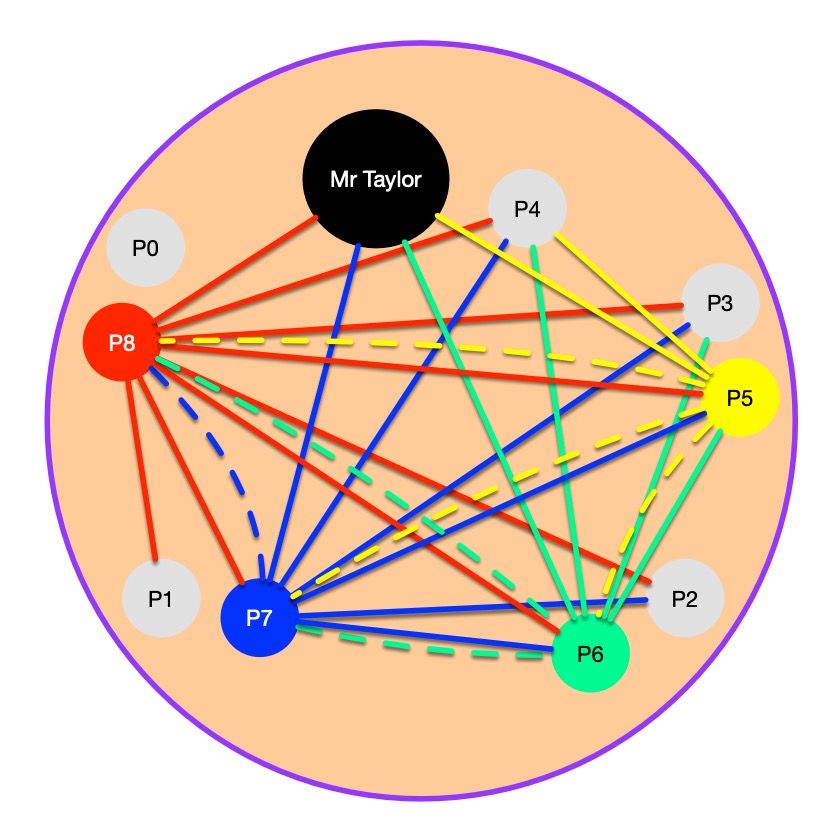
Observe that the analysis above does not only provide us an answer to the puzzle, but it also allows us to uniquely determine the handshake setting as presented in the picture below (called a graph by Computer Scientists). Here, people are nodes (circles) and handshakes are represented as edges (lines) in the graph. Red edges correspond to handshakes with P8, blue edges are handshakes with P7, green with P6 and yellow with P5. Partners are located next to each other, for example, Mr. Taylor is a partner with P4.
Image by CS4FN
Large Language Models
Although this article is about logical thinking, and not about tools to solve logic puzzles, it is interesting to see if current AI models are capable of solving the puzzle. As puzzles go it is relatively easy and occurs on the Internet in different settings and languages, so large language models (LLMs) trained on the Internet should be good at solving it. Let’s test them!
I asked ChatGPT-4o and Gemini 1.5 Flash to solve the puzzle. To my surprise, both of them did struggle. They had problems with understanding some parts of the problem formulation and made mathematical mistakes.
ChatGPT seems to wrongly assume that Mr. Taylor answered his own question about the number of handshakes, and so, that each of 10 people announced a different number of handshakes. As follows from our solution of the puzzle, there exists exactly one graph representing the handshake situation. In this graph, the number of handshakes of Mr. and Mrs. Taylor is the same, namely 4. Hence, the additional assumption made by ChatGPT (that each of 10 people had a different number of handshakes) makes the situation described in the puzzle impossible. Interestingly, ChatGPT was able to solve such an impossible puzzle providing a correct answer… Does it mean that ChatGPT has solved the puzzle?
Gemini, in contrast, states that the puzzle cannot be solved without more information such as the order of arrivals. This is clearly wrong. We know how to solve the puzzle and the order of arrivals is actually completely irrelevant to the puzzle!
This small experiment uses basic LLMs and does not aim to draw any conclusions about their capabilities. I am quite certain that one can find an LLM that can solve this simple puzzle without mistakes. However, this experiment aims to emphasise the need for checking AI solutions yourself. To do that you need to gain the skills of doing proof yourself!
In what follows I provide answers obtained from AI models and highlight as bold parts which are wrong assumptions or reasoning.
Solution by ChatGPT:
Key Observations:
There are 10 people in total at the party (5 couples: Mr. and Mrs. Taylor and 4 other couples).
No one shakes hands with their own partner.
No one shakes hands with themselves or the same person more than once.
The handshake answers must be unique and range from 0 to 9 (since there are 10 people, including Mr. and Mrs. Taylor).
Solution:
Since there are 10 people total, the number of handshakes any one person could have ranges from 0 to 9.
If everyone gives a unique answer, it means:
One person shook hands with 0 people.
Another shook hands with 1 person.
Another with 2, and so on, up to 9.
Steps:
The person who shook hands with 9 people: This person shook hands with everyone else, meaning their partner (who doesn’t shake hands with them) must have shaken hands with 0 people.
The person who shook hands with 8 people: This person shook hands with everyone except their partner and the person who shook hands with 0.
By continuing this pattern, we see that for every unique count of handshakes k, the person with k handshakes corresponds to a partner with 9−k handshakes.
Mrs. Taylor’s Handshakes:
Mr. Taylor shouted “STOP” after collecting answers from all 10 people. Since there are 9 different handshake counts, one of those counts must belong to Mrs. Taylor.
Let’s assume Mr. Taylor is among the group and is the one with the maximum or minimum handshakes.
The pairing pattern ensures Mrs. Taylor’s number of handshakes must fall within the range, but based on symmetry of couples logic !
The key is to match couples symmetrically:
If Mr. Taylor gets answers (0, 1, 2,…
Let’s refine the solution:
The possible handshake counts are 0,1,2,…,9, ensuring each number is unique.
The pairing works such that if one person shakes k hands, their partner shakes 9-k hands.
This logic means:
The person who shook 9 hands paired with the person who shook 0.
The person who shook 8 hands paired with the person who shook 1, and so on.
Mrs. Taylor’s Count:
If there are nine unique handshake counts (from 0 to 9), Mrs. Taylor must have shaken 4 hands because her partner, Mr. Taylor, who controls the setup, must fall at the midpoint to allow symmetrical pairing logic.
Solution by Gemini:
Certainly, let’s solve the handshake puzzle!
Understanding the Problem:
We have 10 people at the party (Mr. and Mrs. Taylor, plus 4 other couples).
No one shakes hands with themselves or their partner.
No one shakes hands with the same person more than once.
Each person keeps track of how many handshakes they’ve done.
Mr. Taylor asks everyone how many handshakes they’ve done, and gets 9 different answers.
We need to figure out how many handshakes Mrs. Taylor did.
Let’s Analyze:
The key to solving this is to consider the possible range of handshakes each person could have.
Lowest Possible Handshakes: If someone is the first to arrive and doesn’t shake hands with anyone else, they’ll have 0 handshakes.
Highest Possible Handshakes: The maximum number of handshakes depends on the order of arrivals and who shakes hands with whom. In the most efficient scenario, everyone could shake hands with everyone else except their partner. This would lead to a maximum of 8 handshakes for each person.
Now, let’s consider the 9 different answers:
Since there are 9 different answers, and the minimum is 0, the maximum number of handshakes someone could have is 8.
Let’s think about Mrs. Taylor:
She can’t have 0 handshakes because she would have to shake hands with someone eventually.
She can’t have 8 handshakes because Mr. Taylor would have to have the same number (since they are the only couple).
Therefore, Mrs. Taylor must have shaken hands with a number between 1 and 7.
Unfortunately, without more information about the order of arrivals and who shook hands with whom, we can’t pinpoint the exact number of handshakes Mrs. Taylor did.
Let me know if you’d like to explore a specific scenario with a particular order of arrivals and handshakes to determine Mrs. Taylor’s exact number!
Mike Lynch was one of Britain’s most successful entrepreneurs. An electrical engineer, he built his businesses around machine learning long before it was a buzz phrase. He also drew heavily on a branch of maths called Bayesian statistics which is concerned with understanding how likely, even apparently unlikely, things are to actually happen. This was so central to his success that he named his super yacht, Bayesian, after it. Tragically, he died on the yacht, when Bayesian sank in a freak, extremely unlikely, accident. The gods of the sea are cruel.
Mike started his path to becoming an entrepreneur at school. He was interested in music, and especially the then new but increasingly exciting, digital synthesisers that were being used by pop bands, and were in the middle of revolutionising music. He couldn’t afford one of his own, though, as they cost thousands. He was sure he could design and build one to sell more cheaply. So he set about doing it.
He continued working on his synthesiser project as a hobby at Cambridge University, where he originally studied science, but changed to his by-then passion of electrical engineering. A risk of visiting his room was that you might painfully step on a resistor or capacitor, as they got everywhere. That was not surprising giving his living room was also his workshop. By this point he was also working more specifically on the idea of setting up a company to sell his synthesiser designs. He eventually got his first break in the business world when chatting to someone in a pub who was in the music industry. They were inspired enough to give him the few thousand pounds he needed to finance his first startup company, Lynett Systems.
By now he was doing a PhD in electrical engineering, funded by EPSRC, and went on to become a research fellow building both his research and innovation skills. His focus was on signal processing which was a natural research area given his work on synthesisers. They are essentially just computers that generate sounds. They create digital signals representing sounds and allow you to manipulate them to create new sounds. It is all just signal processing where the signals ultimately represent music.
However, Mike’s research and ideas were more general than just being applicable to audio. Ultimately, Mike moved away from music, and focussed on using his signal processing skills, and ideas around pattern matching to process images. Images are signals too (resulting from light rather than sound). Making a machine understand what is actually in a picture (really just lots of patches of coloured light) is a signal processing problem. To work out what an image shows, you need to turn those coloured blobs into lines, then into shapes, then into objects that you can identify. Our brains do this seamlessly so it seems easy to us, but actually it is a very hard problem, one that evolution has just found good solutions to. This is what happens whether the image is that captured by the camera of a robot “eye” trying to understand the world or a machine trying to work out what a medical scan shows.
This is where the need for maths comes in to work out probabilities, how likely different things are. Part of the task of recognising lines, shapes and objects is working out how likely one possibility is over another. How likely is it that that band of light is a line, how likely is it that that line is part of this shape rather than that, and so on. Bayesian statistics gives a way to compute probabilities based on the information you already know (or suspect). When the likelihood of events is seen through this lens, things that seem highly unlikely, can turn out to be highly probably (or vice versa), so it can give much more accurate predictions than traditional statistics. Mike’s PhD used this way of calculating probabilities even though some statisticians disdained it. Because of that it was shunned by some in the machine learning community too, but Mike embraced it and made it central to all his work, which gave his programs an edge.
While Lynett Systems didn’t itself make him a billionaire, the experience from setting up that first company became a launch pad for other innovations based on similar technology and ideas. It gave him the initial experience and skills, but also meant he had started to build the networks with potential investors. He did what great entrepreneurs do and didn’t rest on his laurels with just one idea and one company, but started to work on new ideas, and new companies arising from his PhD research.
He realised one important market for image pattern recognition, that was ripe for dominating, was fingerprint recognition. He therefore set about writing software that could match fingerprints far faster and more accurately than anyone else. His new company, Cambridge Neurodynamics, filled a gap, with his software being used by Police Forces nationwide. That then led to other spin-offs using similar technology
He was turning the computational thinking skills of abstraction and generalisation into a way to make money. By creating core general technology that solved the very general problems of signal processing and pattern matching, he could then relatively easily adapt and reuse it to apply to apparently different novel problems, and so markets, with one product leading to the next. By applying his image recognition solution to characters, for example, he created software (and a new company) that searched documents based on character recognition. That led on to a company searching databases, and finally to the company that made him famous, Autonomy.
One of his great loves was his dog, Toby, a friendly enthusiastic beast. Mike’s take on the idea of a search engine was fronted by Toby – in an early version, with his sights set on the nascent search engine market, his search engine user interface involved a lovable, cartoon dog who enthusiastically fetched the information you needed. However, in business finding your market and getting the right business model is everything. Rather than competing with the big US search engine companies that were emerging, he switched to focussing on in-house business applications. He realised businesses were becoming overwhelmed with the amount of information they held on their servers, whether in documents or emails, phone calls or videos. Filing cabinets were becoming history and being replaced by an anarchic mess of files holding different media, individually organised, if at all, and containing “unstructured data”. This kind of data contrasts with the then dominant idea that important data should be organised and stored in a database to make processing it easier. Mike realised that there was lots of data held by companies that mattered to them, but that just was not structured like that and never would be. There was a niche market there to provide a novel solution to a newly emerging business problem. Focussing on that, his search company, Autonomy, took off, gaining corporate giants as clients including the BBC. As a hands-on CEO, with both the technical skills to write the code himself and the business skills to turn it into products businesses needed, he ensured the company quickly grew. It was ultimately sold for $11 billion. (The sale led to an accusation of fraud in hte US, but, innocent, he was acquitted of all the charges).
Investing
From firsthand experience he knew that to turn an idea into reality you needed angel investors: people willing to take a chance on your ideas. With the money he made, he therefore started investing himself, pouring the money he was making from his companies into other people’s ideas. To be a successful investor you need to invest in companies likely to succeed while avoiding ones that will fail. This is also about understanding the likelihood of different things, obviously something he was good at. When he ultimately sold Autonomy, he used the money to create his own investment company, Invoke Capital. Through it he invested in a variety of tech startups across a wide range of areas, from cyber security, crime and law applications to medical and biomedical technologies, using his own technical skills and deep scientific knowledge to help make the right decisions. As a result, he contributed to the thriving Silicon Fen community of UK startup entrepreneurs, who were and continue to do exciting things in and around Cambridge, turning research and innovation into successful, innovative companies. He did this not only through his own ideas but by supporting the ideas of others.
Mike was successful because he combined business skills with a wide variety of technical skills including maths, electronic engineering and computer science, even bioengineering. He didn’t use his success to just build up a fortune but reinvested it in new ideas, new companies and new people. He has left a wonderful legacy as a result, all the more so if others follow his lead and invest their success in the success of others too.
Mid-September, as many young people are heading back to school after their summer holiday, is Asthma Week where NHS England suggests that teachers, employers and government workers #AskAboutAsthma. The goal is to raise awareness of the experiences of those with asthma, and to suggest techniques to put in place to help children and young people with asthma live their best lives.
One of the key bits of kit in the arsenal of people with asthma is an inhaler. When used, an inhaler can administer medication directly into the lungs and airways as the user breathes in. In the case of those with asthma, an inhaler can help to reduce inflammation in the airways which might prevent air from entering the lungs, especially during an asthma attack.
It’s only recently, however, that inhalers are getting the technology treatment. Smart inhalers can help to remind those with asthma to take their medication as prescribed (a common challenge for those with asthma) as well as tracking their use which can be shared with doctors, carers, or parents. Some smart inhalers can also identify if the correct inhaler technique is being used. Researchers have been able to achieve this by putting the audio of people using an inhaler through a neural network (a form of artificial intelligence), which can then classify between a good and bad technique.
As with any medical technology, these smart inhalers need to be tested with people with asthma to check that they are safe and healthy, and importantly to check that they are better than the existing solutions. One such study started in Leicester in July 2024, where smart inhalers (in this case, ones that clip onto existing inhalers) are being given to around 300 children in the city. The researchers will wait to see if these children have better outcomes than those who are using regular inhalers.
This sort of technology is a great example of what computer scientists call the “Internet of Things” (IoT). This refers to small computers which might be embedded within other devices which can interact over the internet… think smart lights in your home that connect to a home assistant, or fridges that can order food when you run out.
A lot of medical devices are being integrated into the internet like this… a smart watch can track the wearer’s heart rate continuously and store it in a database for later, for example. Will this help us to live happier, healthier lives though? Or could we end up finding concerning patterns where there are none?
One of the ways that computers could be more like humans – and maybe pass the Turing test – is by responding to emotion. But how could a computer learn to read human emotions out of words? Matthew Purver of Queen Mary University of London tells us how.
Have you ever thought about why you add emoticons to your text messages – symbols like 🙂 and :-@? Why do we do this with some messages but not with others? And why do we use different words, symbols and abbreviations in texts, Twitter messages, Facebook status updates and formal writing?
In face-to-face conversation, we get a lot of information from the way someone sounds, their facial expressions, and their gestures. In particular, this is the way we convey much of our emotional information – how happy or annoyed we’re feeling about what we’re saying. But when we’re sending a written message, these audio-visual cues are lost – so we have to think of other ways to convey the same information. The ways we choose to do this depend on the space we have available, and on what we think other people will understand. If we’re writing a book or an article, with lots of space and time available, we can use extra words to fully describe our point of view. But if we’re writing an SMS message when we’re short of time and the phone keypad takes time to use, or if we’re writing on Twitter and only have 140 characters of space, then we need to think of other conventions. Humans are very good at this – we can invent and understand new symbols, words or abbreviations quite easily. If you hadn’t seen the 😀 symbol before, you can probably guess what it means – especially if you know something about the person texting you, and what you’re talking about.
But computers are terrible at this. They’re generally bad at guessing new things, and they’re bad at understanding the way we naturally express ourselves. So if computers need to understand what people are writing to each other in short messages like on Twitter or Facebook, we have a problem. But this is something researchers would really like to do: for example, researchers in France, Germany and Ireland have all found that Twitter opinions can help predict election results, sometimes better than standard exit polls – and if we could accurately understand whether people are feeling happy or angry about a candidate when they tweet about them, we’d have a powerful tool for understanding popular opinion. Similarly we could automatically find out whether people liked a new product when it was launched; and some research even suggests you could even predict the stock market. But how do we teach computers to understand emotional content, and learn to adapt to the new ways we express it?
One answer might be in a class of techniques called semi-supervised learning. By taking some example messages in which the authors have made the emotional content very clear (using emoticons, or specific conventions like Twitter’s #fail or abbreviations like LOL), we can give ourselves a foundation to build on. A computer can learn the words and phrases that seem to be associated with these clear emotions, so it understands this limited set of messages. Then, by allowing it to find new data with the same words and phrases, it can learn new examples for itself. Eventually, it can learn new symbols or phrases if it sees them together with emotional patterns it already knows enough times to be confident, and then we’re on our way towards an emotionally aware computer. However, we’re still a fair way off getting it right all the time, every time.
Have you ever heard a grown up say “I’d completely forgotten about that!” and then share a story from some long-forgotten memory? While most of us can remember all sorts of things from our own life history it sometimes takes a particular cue for us to suddenly recall something that we’d not thought about for years or even decades.
As we go through life we add more and more memories to our own personal library, but those memories aren’t neatly organised like books on a shelf. For example, can you remember what you were doing on Thursday 20th September 2018 (or can you think of a way that would help you find out)? You’re more likely to be able to remember what you were doing on the last Tuesday in December 2018 (but only because it was Christmas Day!). You might not spontaneously recall a particular toy from your childhood but if someone were to put it in your hands the memories about how you played with it might come flooding back.
Accessing old memories
In Alzheimer’s Disease (a type of dementia) people find it harder to form new memories or retain more recent information which can make daily life difficult and bewildering and they may lose their self-confidence. Their older memories, the ones that were made when they were younger, are often less affected however. The memories are still there but might need drawing out with a prompt, to help bring them to the surface.
Perhaps a newspaper advert will jog your memory in years to come… Image by G.C. from Pixabay
An EPSRC-funded project at Heriot-Watt University in Scotland is developing a tablet-based ‘story facilitator’ agent (a software program designed to adapt its response to human interaction) which contains artificial intelligence to help people with Alzheimer’s disease and their carers. The device, called ‘AMPER’*, could improve wellbeing and a sense of self in people with dementia by helping them to uncover their ‘autobiographical memories’, about their own life and experiences – and also help their carers remember them ‘before the disease’.
Our ‘reminiscence bump’
We form some of our most important memories between our teenage years and early adulthood – we start to develop our own interests in music and the subjects that we like studying, we might experience first loves, perhaps going to university, starting a career and maybe a family. We also all live through a particular period of time where we’re each experiencing the same world events as others of the same age, and those experiences are fitted into our ‘memory banks’ too. If someone was born in the 1950s then their ‘reminiscence bump’ will be events from the 1970s and 1980s – those memories are usually more available and therefore people affected by Alzheimer’s disease would be able to access them until more advanced stages of the disease process. Big important things that, when we’re older, we’ll remember more easily if prompted.
In years to come you might remember fun nights out with friends. Image by ericbarns from Pixabay
Talking and reminiscing about past life events can help people with dementia by reinforcing their self-identity, and increasing their ability to communicate – at a time when they might otherwise feel rather lost and distressed.
“AMPER will explore the potential for AI to help access an individual’s personal memories residing in the still viable regions of the brain by creating natural, relatable stories. These will be tailored to their unique life experiences, age, social context and changing needs to encourage reminiscing.”
Dr Mei Yii Lim, who came up with the idea for AMPER(3).
Saving your preferences
AMPER comes pre-loaded with publicly available information (such as photographs, news clippings or videos) about world events that would be familiar to an older person. It’s also given information about the person’s likes and interests. It offers examples of these as suggested discussion prompts and the person with Alzheimer’s disease can decide with their carer what they might want to explore and talk about. Here comes the clever bit – AMPER also contains an AI feature that lets it adapt to the person with dementia. If the person selects certain things to talk about instead of others then in future the AI can suggest more things that are related to their preferences over less preferred things. Each choice the person with dementia makes now reinforces what the AI will show them in future. That might include preferences for watching a video or looking at photos over reading something, and the AI can adjust to shorter attention spans if necessary.
“Reminiscence therapy is a way of coordinated storytelling with people who have dementia, in which you exercise their early memories which tend to be retained much longer than more recent ones, and produce an interesting interactive experience for them, often using supporting materials — so you might use photographs for instance”
Prof Ruth Aylett, the AMPER project’s lead at Heriot-Watt University(4).
When we look at a photograph, for example, the memories it brings up haven’t been organised neatly in our brain like a database. Our memories form connections with all our other memories, more like the branches of a tree. We might remember the people that we’re with in the photo, then remember other fun events we had with them, perhaps places that we visited and the sights and smells we experienced there. AMPER’s AI can mimic the way our memories branch and show new information prompts based on the person’s previous interactions.
Although AMPER can help someone with dementia rediscover themselves and their memories it can also help carers in care homes (who didn’t know them when they were younger) learn more about the person they’re caring for.
Suggested classroom activities – find some prompts!
What’s the first big news story you and your class remember hearing about? Do you think you will remember that in 60 years’ time?
What sort of information about world or local events might you gather to help prompt the memories for someone born in 1942, 1959, 1973 or 1997? (Remember that their reminiscence bump will peak in the 15 to 30 years after they were born – some of them may still be in the process of making their memories the first time!).
See also
If you live near Blackheath in South East London why not visit the Age Exchange and reminiscence centre which is an arts charity providing creative group activities for those living with dementia and their carers. It has a very nice cafe.
Related careers
The AMPER project is interdisciplinary, mixing robots and technology with psychology, healthcare and medical regulation.
We have information about four similar-ish job roles on our TechDevJobs blog that might be of interest. This was a group of job adverts for roles in the Netherlands related to the ‘Dramaturgy^ for Devices’ project. This is a project linking technology with the performing arts to adapt robots’ behaviour and improve their social interaction and communication skills.
Follow the news and it is clear that the chatbots are about to take over journalism, novel writing, script writing, writing research papers, … just about all kinds of writing. So how about writing for the CS4FN magazine. Are they good enough yet? Are we about to lose our jobs? Jo asked ChatGPT to write a CS4FN article to find out.Read its efforts before reading on…
As editor I not only wrote but also vet articles and tweak them when necessary to fit the magazine style. So I’ve looked at ChatGPT’s offering as I would one coming from a person …
ChatGPT’s essay writing has been compared to that of a good but not brilliant student. Writing CS4FN articles is a task we have set students in the past: in part to give them experience over how you must write in different styles for different purposes. Different audience? Different writing. Only a small number come close to what I am after. They generally have one or more issues. A common problem when students write for CS4FN is sadly a lack of good grammar and punctuation throughout beyond just typos (basic but vital English skills seem to be severely lacking these days even with spell checking and grammar checking tools to help). Other common problems include a lack of structure, no hook at the start, over-formal writing so the wrong style, no real fun element at all and/or being devoid of stories about people, an obsession with a few subjects (like machine learning!) rather than finding something new to write about. They are also then often vanilla articles about that topic, just churning out looked-up facts rather than finding some new, interesting angle.
How did the chatbot do? It seems to have made most of the same mistakes. At least, chatGPT’s spelling and grammar are basically good so that is a start: it is a good primary school student then! Beyond that it has behaved like the weaker students do… and missed the point. It has actually just written a pretty bog standard factual article explaining the topic it chose, and of course given a free choice, it chose … Machine Learning! Fine, if it had a novel twist, but there are no interesting angles added to the topic to bring it alive. Nor did it describe the contributions of a person. In fact, no people are mentioned at all. It is also using a pretty formal style of writing (“In conclusion…”). Just like humans (especially academics) it also used too much jargon and didn’t even explain all the jargon it did use (even after being prompted to write for a younger audience). If I was editing I’d get rid of the formality and unexplained jargon for starters. Just like the students who can actually write but don’t yet get the subtleties, it hasn’t got the fact that it should have adapted its style, even when prompted.
It knows about structure and can construct an essay with a start, a middle and end as it has put in an introduction and a conclusion. What it hasn’t done though is add any kind of “grab”. There is nothing at the start to really capture the attention. There is no strange link, no intriguing question, no surprising statement, no interesting person…nothing to really grab you (though Jo saved it by adding to the start, the grab that she had asked an AI to write it). It hasn’t added any twist at the end, or included anything surprising. In fact, there is no fun element at all. Our articles can be serious rather than fun but then the grab has to be about the seriousness: linked to bad effects for society, for example.
ChatGPT has also written a very abstract essay. There is little in the way of context or concrete examples. It says, for example, “rules … couldn’t handle complex situations”. Give me an example of a complex situation so I know what you are talking about! There are no similes or metaphors to help explain. It throws in some application areas for context like game-playing and healthcare but doesn’t at all explain them (it doesn’t say what kind of breakthrough has been made to game playing, for example). In fact, it doesn’t seem to be writing in a “semantic wave” style that makes for good explanations at all. That is where you explain something by linking an abstract technical thing you are explaining, to some everyday context or concrete example, unpacking then repacking the concepts. Explaining machine learning? Then illustrate your points with an example such as how machine learning might use movies to predict your voting habits perhaps…and explain how the example does illustrate the abstract concepts such as pointing out the patterns it might spot.
There are several different kinds of CS4FN article. Overall, CS4FN is about public engagement with research. That gives us ways in to explain core computer science though (like what machine learning is). We try to make sure the reader learns something core, if by stealth, in the middle of longer articles. We also write about people and especially diversity, sometimes about careers or popular culture, or about the history of computation. So, context is central to our articles. Sometimes we write about general topics but always with some interesting link, or game or puzzle or … something. For a really, really good article that I instantly love, I am looking for some real creativity – something very different, whether that is an intriguing link, a new topic, or just a not very well known and surprising fact. ChatGPT did not do any of that at all.
Was ChatGPT’s article good enough? No. At best I might use some of what it wrote in the middle of some other article but in that case I would be doing all the work to make it a CS4FN article.
ChatGPT hasn’t written a CS4FN article in any sense other than in writing about computing.
Was it trained on material from CS4FN to allow it to pick up what CS4FN was? We originally assumed so – our material has been freely accessible on the web for 20 years and the web is supposedly the chatbots’ training ground. If so I would have expected it to do much better at getting the style right (though if it has used our material it should have credited us!). I’m left thinking that actually when it is asked to write articles or essays without more guidance it understands, it just always writes about machine learning! (Just like I always used to write science fiction stories for every story my English teacher set, to his exasperation!) We assumed, because it wrote about a computing topic, that it did understand, but perhaps, it is all a chimera. Perhaps it didn’t actually understand the brief even to the level of knowing it was being asked to write about computing and just hit lucky. Who knows? It is a black box. We could investigate more, but this is a simple example of why we need Artificial Intelligences that can justify their decisions!
Of course we could work harder to train it up as I would a human member of our team. With more of the right prompting we could perhaps get it there. Also given time the chatbots will get far better, anyway. Even without that they clearly can now do good basic factual writing so, yes, lots of writing jobs are undoubtedly now at risk (and that includes a wide range of jobs, like lawyers, teachers, and even programmers and the like too) if we as a society decide to let them. We may find the world turns much more vanilla as a result though with writing turning much more bland and boring without the human spark and without us noticing till it is lost (just like modern supermarket tomatoes so often taste bland having lost the intense taste they once had!) … unless the chatbots gain some real creativity.
The basic problem of new technology is it reaps changes irrespective of the human cost (when we allow it to, but we so often do, giddy with the new toys). That is fine if as a society we have strong ways to support those affected. That might involve major support for retraining and education into new jobs created. Alternatively, if fewer jobs are created than destroyed, which is the way we may be going, where jobs become ever scarcer, then we need strong social support systems and no stigma to not having a job. However, currently that is not looking likely and instead changes of recent times have just increased, not reduced inequality, with small numbers getting very, very rich but many others getting far poorer as the jobs left pay less and less.
Perhaps it’s not malevolent Artificial Intelligences of science fiction taking over that is the real threat to humanity. Corporations act like living entities these days, working to ensure their own survival whatever the cost, and we largely let them. Perhaps it is the tech companies and their brand of alien self-serving corporation as ‘intelligent life’ acting as societal disrupters that we need to worry about. Things happen (like technology releases) because the corporation wants them to but at the moment that isn’t always the same as what is best for people long term. We could be heading for a wonderful utopian world where people do not need to work and instead spend their time doing fulfilling things. It increasingly looks like instead we have a very dystopian future to look forward to – if we let the Artificial Intelligences do too many things, taking over jobs, just because they can so that corporations can do things more cheaply, so make more fabulous wealth for the few.
Am I about to lose my job writing articles for CS4FN? I don’t think so. Why do I write CS4FN? I love writing this kind of stuff. It is my hobby as much as anything. So I do it for my own personal pleasure as well as for the good I hope it does whether inspiring and educating people, or just throwing up things to think about. Even if the chatBots were good enough, I wouldn’t stop writing. It is great to have a hobby that may also be useful to others. And why would I stop doing something I do for fun, just because a machine could do it for me? But that is just lucky for me. Others who do it for a living won’t be so lucky.
We really have to stop and think about what we want as humans. Why do we do creative things? Why do we work? Why do we do anything? Replacing us with machines is all well and good, but only if the future for all people is actually better as a result, not just a few.
EPSRC supports this blog through research grant EP/W033615/1.
Blog post by OpenAI’s ChatGPT. Introduction by Jo Brodie
1. Jo wrote this…
ChatGPT is an AI chatbot which can have a conversation with you using everyday (natural) language. It has access to the huge amounts of digital information found on the internet and its ability to use language to write good answers in response to questions has been tested and improved by giving it feedback. It learns, and refines its output.
You don’t need to programme it, you can just ask it a question (giving it a prompt) and, after a moment’s ‘thinking’ it will produce an answer. Lots of people have been testing ChatGPT by asking it questions that we already know the answer to, to see how well it can do. It’s actually quite impressive! If you think it’s made a mistake or misunderstood your prompt you can reword your question or give it more information to help it improve its answer.
Can ChatGPT write an article that’s suitable for our magazine or website?
I gave ChatGPT the following prompt: “Please write a 200 to 500 word article suitable for the CS4FN magazine” and moments later it generated a completely new article about machine learning. That told me it knew (or at least could find out) that CS4FN has something to do with computer science. I’m not surprised that it picked machine learning as a topic given that it is a machine that can learn. I didn’t tell it what to write about, it came up with that idea itself.
The article it gave me contained some technical words and not all of them were explained, so I asked it to rewrite the article for a younger audience (who might not have come across some of the words yet).
The result is below – what do you think?
2. ChatGPT wrote this…
From Logic to Learning: The Incredible Advancements of Artificial Intelligence
Artificial Intelligence (AI) has come a long way since it was first invented in the 1950s. At the beginning, AI was based on logic and rules. Experts in a specific field would give the computer a set of instructions to help it make decisions. But, these rules were limited and couldn’t handle complex situations.
Today, AI has seen a huge shift towards machine learning. This means that instead of following rules, AI learns from data. This shift happened because computers got stronger, and more data became available. The breakthroughs in machine learning algorithms helped too.
Machine learning has two categories: supervised learning and unsupervised learning. In supervised learning, the computer learns from labeled data. This means that the correct answer is given to the computer for each input. Once the computer has learned enough, it can predict the answer for new data. Supervised learning is useful for applications like image and speech recognition.
In unsupervised learning, the computer learns from unlabeled data. This means that there is no correct answer provided. The goal of unsupervised learning is to find patterns in the data. This type of learning is useful in applications like anomaly detection and clustering.
Deep learning is a special type of machine learning that uses neural networks. Neural networks are inspired by the human brain and have layers of connected nodes. Each node applies a mathematical function to its inputs and sends the result to the next layer of nodes. Deep learning has revolutionized AI, leading to breakthroughs in areas like natural language processing, computer vision, and game playing.
Even though machine learning has achieved so much, there are still challenges to overcome. One challenge is the lack of transparency in machine learning models. Unlike rule-based systems, it can be hard to understand how a machine learning model made a decision. This can be a problem, especially in areas like healthcare where the decision-making process needs to be trustworthy and explainable.
Another challenge is the need for a lot of data to train machine learning models. While data is easy to find in some areas, like social media, it can be hard to come by in other areas like medical imaging. This lack of data can make machine learning less effective in some applications.
In conclusion, AI has come a long way since the 1950s. We’ve gone from rule-based systems to machine learning, which has led to breakthroughs in many areas. Although there are still challenges to overcome, the future of AI is exciting!
The first attempt is below…
The Evolution of Artificial Intelligence: From Rule-Based to Machine Learning
Artificial Intelligence (AI) has come a long way since its inception in the 1950s. Initially, AI was developed based on rule-based systems, where experts in a specific domain would provide rules to the system to help it make decisions. While these systems worked well in some areas, they were limited in their ability to handle complex problems and adapt to new situations.
In recent years, AI has seen a significant shift towards machine learning, where systems learn from data rather than relying on pre-defined rules. This shift has been driven by advances in computer hardware, the availability of large amounts of data, and breakthroughs in machine learning algorithms.
Machine learning has two main categories: supervised learning and unsupervised learning. In supervised learning, the system is trained on labeled data, where the correct answer is provided for each input. The system uses this labeled data to learn a function that maps inputs to outputs. Once trained, the system can make predictions on new, unseen data. This approach has been successful in a wide range of applications, such as image and speech recognition.
In unsupervised learning, the system is trained on unlabeled data, where no correct answer is provided. The goal of unsupervised learning is to discover patterns and structure in the data. This approach has been useful in areas such as anomaly detection and clustering.
Deep learning is a subset of machine learning that uses neural networks to learn from data. Neural networks are inspired by the structure of the human brain and consist of layers of interconnected nodes. Each node applies a mathematical function to its inputs and passes the result to the next layer of nodes. Deep learning has revolutionized the field of AI, enabling breakthroughs in areas such as natural language processing, computer vision, and game playing.
Despite the many successes of machine learning, there are still limitations and challenges to overcome. One challenge is the lack of interpretability of machine learning models. Unlike rule-based systems, it can be difficult to understand how a machine learning model arrived at a particular decision. This lack of transparency can be problematic in areas such as healthcare, where the decision-making process needs to be explainable and trustworthy.
Another challenge is the need for large amounts of data to train machine learning models. While data is abundant in some domains, such as social media, it can be scarce in others, such as medical imaging. This scarcity of data can limit the effectiveness of machine learning approaches in certain applications.
In conclusion, the evolution of AI from rule-based systems to machine learning has enabled breakthroughs in many areas and holds tremendous potential for the future. However, there are still challenges to overcome, particularly in the areas of interpretability and data scarcity. Addressing these challenges will be critical to realizing the full potential of AI in the years to come.
Could your smartphone automatically tell you what species of bird is singing outside your window? If so how?
Mobile phones contain microphones to pick up your voice. That means they should be able to pick up the sound of birds singing too, right? And maybe even decide which bird is which?
Smartphone apps exist that promise to do just this. They record a sound, analyse it, and tell you which species of bird they think it is most likely to be. But a smartphone doesn’t have the sophisticated brain that we have, evolved over millions of years to understand the world around us. A smartphone has to be programmed by someone to do everything it does. So if you had to program an app to recognise bird sounds, how would you do it? There are two very different ways computer scientists have devised to do this kind of decision making and they are used by researchers for all sorts of applications from diagnosing medical problems to recognising suspicious behaviour in CCTV images. Both ways are used by phone apps to recognise bird song that you can already buy.
The sound of the European robin (Erithacus rubecula) better known as robin redbreast, Recorded by Vladimir Yu. Arkhipov, Arkhivov CC BY-SA 3.0 via wikimedia
If you ask a birdwatcher how to identify a blackbird’s sound, they will tell you specific rules. “It’s high-pitched, not low-pitched.” “It lasts a few seconds and then there’s a silent gap before it does it again.” “It’s twittery and complex, not just a single note.” So if we wrote down all those rules in a recipe for the machine to follow, each rule a little program that could say “Yes, I’m true for that sound”, an app combining them could decide when a sound matches all the rules and when it doesn’t.
This is called an ‘expert system’ approach. One difficulty is that it can take a lot of time and effort to actually write down enough rules for enough birds: there are hundreds of bird species in the UK alone! Each would need lots of rules to be hand crafted. It also needs lots of input from bird experts to get the rules exactly right. Even then it’s not always possible for people to put into words what makes a sound special. Could you write down exactly what makes you recognise your friends’ voices, and what makes them different from everyone else’s? Probably not! However, this approach can be good because you know exactly what reasons the computer is using when it makes decisions.
This is very different from the other approach which is…
Show it lots of examples
A lot of modern systems use the idea of ‘machine learning’, which means that instead of writing rules down, we create a system that can somehow ‘learn’ what the correct answer should be. We just give it lots of different examples to learn from, telling it what each one is. Once it has seen enough examples to get it right often enough, we let it loose on things we don’t know in advance. This approach is inspired by how the brain works. We know that brains are good at learning, so why not do what they do!
One difficulty with this is that you can’t always be sure how the machine comes up with its decisions. Often the software is a ‘black box’ that gives you an answer but doesn’t tell you what justifies that answer. Is it really listening to the same aspects of the sound as we do? How would we know?
On the other hand, perhaps that’s the great thing about this approach: a computer might be able to give you the right answer without you having to tell it exactly how to do that!
It means we don’t need to write down a ‘recipe’ for every sound we want to detect. If it can learn from examples, and get the answer right when it hears new examples, isn’t that all we need?
Which way is best?
There are hundreds of bird species that you might hear in the UK alone, and many more in tropical countries. Human experts take many years to learn which sound means which bird. It’s a difficult thing to do!
So which approach should your smartphone use if you want it to help identify birds around you? You can find phone apps that use one approach or another. It’s very hard to measure exactly which approach is best, because the conditions change so much. Which one works best when there’s noisy traffic in the background? Which one works best when lots of birds sing together? Which one works best if the bird is singing in a different ‘dialect’ from the examples we used when we created the system?
One way to answer the question is to provide phone apps to people and to see which apps they find most useful. So companies and researchers are creating apps using the ways they hope will work best. The market may well then make the decision. How would you decide?