QMUL’s Sophie Skach is interested in both textiles and computers. In a recent summer project she explored how much your chair could tell about you.
When sitting talking, we change postures a lot, and maybe that gives vital clues to what is actually happening when groups of people are talking. By embedding sensors in the fabric of a chair, perhaps it can tell something about the social roles involved – who is dominant in the conversation, who is passive, who is speaking, who is listening, who isn’t. Intelligence starts with being able to sense the world, so sytems like this may one day help make computers more intelligent, making it easier for them to work out, unobtrusively, the nuances of what we humans are up to.
One day soon your chair may be keeping an eye on you!
It’s fun to add emoticons to messages, and they help ensure people understand our feelings. They are helping some people understand feelings face-to-face too, with a bit of help from an Artificial Intelligence.
Reading faces
We take it for granted that we can look at someone’s face and tell whether they are happy or sad, angry or surprised. Autistic children, however, often struggle to understand people’s expressions. When anxious we also all tend to avoid eye contact. Some autistic children do that all the time. They are then even less likely to see the clues in people’s faces, and so start to understand emotions. This can make it harder to make friends.
From robots to glasses
Many hi-tech ways have been tried to help autistic children learn about emotions. One, for example, involves letting them play with robot ‘friends’ as some find the cartoon-like expressions on a robot face more comfortable and easier to follow. A different approach is based on wearable technology. Researchers at Stanford University have created a program for autistic children that works out a person’s expression and displays an emoticon of it in a pair of smart glasses.
An AI reading faces for you
A camera in the glasses records what the wearer sees and the Artificial Intelligence (AI) program detects any faces. This kind of technology is also used in smartphones to detect faces in your photo collection. It uses ‘machine learning’: the program learns what a face is by being shown lots of images, some with and some without faces. The program uses all that data to work out the patterns in an image that mean there is a face. It then uses that pattern to spot new faces.
In a similar way it can be trained on faces with different expressions. A training set of faces are used that are labelled with the emotion in that image. This allows the program to spot what pattern in a face makes a happy face, what makes a sad face, and so on. Having recognised an expression, the glasses finally act as a screen and show an emoticon, such as a smiley, corresponding to that expression. Superimposing digital images on the real world like this is called augmented reality. It makes looking at faces like a game and means that the child can use the emoticon to understand what the person in front of them is feeling. It also means they can start to learn for themselves – almost like the AI! The AI is labelling the faces for them, just as people had done for it. With the glasses, autistic children can be sure what each face is actually saying rather than having to guess. Eventually they might then form their own rules and so do it on their own.
Making a difference
The Stanford system was trialled with autistic children in their own homes. They used the system for several months and their parents found it made a clear difference. By the end many of the children were engaging much more with their family including making a lot more eye contact.
Emoticons are making a real difference to their lives.
A QMUL astronomy banner with the Moon behind it Credit: Jo Brodie – under a Public Domain CC0 licence
Heavens above, you’ve discovered a new celestial object! What would you call it? Would you name it Clom, Skaro, Poosh, or even Raxacoricofallapatorius? Or maybe those names are already taken. This sort of thing is complicated – even when it comes to naming new planets, moons or asteroids there are rules, and the need for a bit of computer science too.
It’s not Spock
Asteroids start off being designated using the year and the month they were first detected. Only once their orbit has been correctly predicted can they then be named. Predicting the orbit needs a cosmic fusion of astronomy, physics and lots of computer processing to predict and then check they are where they should be. Choosing a name is not too easy either. Since 1971 when one astronomer named an asteroid ‘2309 Mr. Spock’ after his pet cat, the International Astronomical Union decided to ban pets’ names, but that didn’t stop some creative discoverers getting the names ‘6042 Cheshirecat’ and ‘9007 James Bond’ agreed.
Over the moon
Moons are more difficult to name – more rules apply and more physics and computer science are needed to show they are what they are. A moon not only has to orbit a planet, it must do it in a well-defined way. For example the Cassini probe that’s exploring Saturn and its wonderful ring system discovered a range of small moons that keep the rings of Saturn crisp. Some of these tiny ‘shepherd moons’ orbit near the edges of the gaps in the rings. Materials that drift close to them are pulled back by gravity into the rings, spun off into space or made to crash on the shepherd moon itself. To be able to name one of these moons you need to be able to show that its orbit is stable. When the scientists think they have found a moon, the data from the sensors on the Cassini probe is fed into sophisticated computer simulations to show if that moon has a stable orbit. The outcome of the calculation decides if the moon is, well, a moon.
Good Moon Hunting
The software can even hunt down and find unknown moons. Using the laws of geometry and Kepler’s laws of planetary motion (three rules that German astronomer Johannes Kepler discovered in the 16th century) and applying them to the data from the probe it‘s possible to guess where a moon might be. Scientists then perform a full analysis of the data, including whether the possible moon’s orbit is affected by other known moons, and are able to determine where the previously unknown moons actually are. Using this method, scientists have even discovered so-called retrograde moons, which orbit in the opposite direction to Saturn’s rotation.
Once the orbit is predicted and checked the computer-discovered moon can be named. The scientists have now found so many of these mini-moons that the rules about names have had to change.
More giants and monsters please
To start with the moons of Saturn were named after mythological Greek and Roman giants, but as more were discovered astronomers went over to naming them after the mythical Titans, who fought alongside the giants (and were pretty huge themselves). Finally as more moon hunting showed an ever larger and more fascinating picture the names had to expand to include giants and monsters in Norse, Inuit and Gallic mythologies. Astronomer Carl Murray of Queen Mary, University of London, part of the team who discovered the Saturnian moons Polydeuces and Anthe said “I never thought that a knowledge of ancient mythologies would help me do astronomy”. Quite where this moon-related voyage of discovery will end no one quite knows.
Galileo was the first to observe Saturn’s rings though he had no idea what they were. He wrote in his notebook that the planet had ‘ears’.
Knowing the neighbourhood
Finding moons and keeping an eye on asteroids is an activity that involves astronomers, physicists and computer scientists. Without these scientists all working together, each bringing their skills to work on the problem, our solar system could be a less well-known and more dangerous place to live. We know where things are, after all. We don’t want to end up like Poosh and loose a moon.
Out of the way
Computer science also allows the paths of asteroids to be predicted, which is what’s needed to name them. More importantly these computer models can predict if the asteroids will cut across Earth’s orbit. We don’t want to be unexpectedly hitting one of these lumps, even if the idea makes for a good movie.
Computer scientists are helping doctors, surgeons, biologists and psychologists get inside the body and mind, and improving the way that medical care will be provided now and in the future. It’s a fascinating story of biology, maths and computing and it all starts with an X.
What a picture!
X-rays were the first practical method of examining the inside of a living body. The process involves firing high energy X-rays through the body with a photographic plate at the other side. Dense bits of the body like bones absorb radiation. That leads to a lighter area on the developed photographic negative. In effect a shadow is cast through you onto the photograph, giving a view inside. A problem with this is that, as with any camera, it’s hard to get the photograph exposure right. Worse you have to find the space to store hundreds and thousands of sheets of film. Worse still, suppose your doctor in Manchester needs the X-ray taken of you when you are wanting to play football so you are in Frankfurt. The film has to be sent by post. Enter computer scientists to make things easier.
Portable pixel pictures
New digital X-ray systems are being developed. These use X-ray detectors not film and produce digital images rather than the standard photographic images. The advantage here is that those images can be processed using clever algorithms to correct for problems in exposure, or even to pick up particular shapes in the image. The diagnosis can be helped by the artificial intelligence in the computer, which can spot unusual patterns in the image and alert the doctor. Better still since these digital X-rays are computer based. They can be easily stored and transmitted throughout the world to places where they are needed.
A slice of life
X-rays, even digital X-rays, can only give you flat images of the body innards. Like a shadow they squash all the depth details. Your insides are three-dimensional (3D) though, so it would be useful to be able to slice through your body and get a view inside. This is possible using a computer based method called tomography, from the Greek tomos (slice) and graphia (describing). It still uses X-rays but in a Computed Tomography (CT) scan the X-ray source and the detector rotate round the body taking lots of images at different angles. It’s like casting different shadows as the sun moves round you. So imagine you’re using tomography on a cylinder, and your X-ray source is a torch. Move the torch round the cylinder and look at the shadow cast on a piece of paper moving at the opposite side to the torch. Each ‘shadow’ picture would look the same because a cylinder is circularly symmetric. Now imagine a more interesting shape. Each of the shadow pictures would depend on where you were at the time in relation to the shape. With some clever maths, a reconstruction algorithm and a computer you can go from the shadow pictures back to the shape. These shapes are the organs and innards of your body, and they can be recorded in their full 3D glory. There are now systems that spiral the X-ray source round the body making it quicker. You can even do tomography at very high speed allowing slices through the beating heart to be calculated. Interestingly the maths behind this technology, called the “Radon transform” after Czech mathematician Johann Radon (1887-1956), was developed purely as an abstract mathematical theory. No one at the time could see any use for it!
Check in at the Digital Hospital
Life-saving healthcare and medical imaging is going digital. Using video conferencing, mobile scanners and even remote operated robotic surgery the field of tele-medicine allows expert medical care to be provided any time, any place. Today’s progress towards the digital hospital combines different ways of taking information about the state of your body, such as digital X-rays, or tomographic images, readings from digital thermometers or digital blood pressure readers. We can combine all this information with your personal information into one big file, so there is no need for multiple paper copies to get out of date or lost. The hospital information system keeps track of all your data, and also importantly who has access to it.
Tomorrow’s world and you
According to Alan McBride, a computer scientist who is working on these state of the art medical systems:
“This technology is a major step forward in health care where the UK is leading the way. The government’s grand scheme will allow images taken in Newcastle to be shown on your GP’s desk in London, together with the hospital report, which will automatically be emailed to their inbox. Computer science is playing the major role in all this, creating new ways to aid clinical practice, with plenty of scope in the future for talented computer scientists to get involved.”
The computer scientists who make this happen will not only be technical specialists but also experts in understanding human behaviour. We will only get the benefits such a grand scheme promises if the conflicting needs and concerns of all those involved are taken into account: patients, nurses, doctors, managers and politicians…that will take major people-skills.
Bee on blossom by Jodiepedia, Public Domain Dedication (CC0) via Flickr.
If it weren’t for the bees we would be in trouble. In the worst case, life on Earth could go the way of Mars. No plants, no animals, no life. Bees are the main way that flowers get pollinated. As the bees sup the nectar they carry pollen from flower to flower, allowing new generations of flowers to grow. But the way a flower looks to our eyes isn’t the same way a bee sees it. For example, bee vision works into the ultraviolet part of the spectrum and under the correct lighting in a laboratory the wonderful, normally invisible, patterns that bees can see are revealed. Biologists all over the world have been collecting information about the sorts of patterns that particular flowers display. This display is called a spectral profile, and Samia Faruq, a computer science undergraduate at Queen Mary University of London has done her bit to help these scientists peer into the world of the bees.
Her project involved creating a massive online database containing worldwide spectral profile information, so scientists can search this information easily. They can also combine information to help discover new facts using a method called clustering, where the computer pulls together all the data with similar properties.
Samia enjoyed the project: “I met and worked with amazing biologists during the project. It was great to find out what they needed and to be able to create it for them. I got the chance to collaborate and publish material together with them too. To know it will be used in their research is also very rewarding.”
Since their discovery over a century ago, X-rays have become invaluable in the medical world, allowing doctors to see inside our bodies. Whilst the basic technology of taking medical X-rays is unchanged – essentially taking a photograph of the shadow left when X-rays are shone through the body – X-rays have entered the computer age. From digital X-rays that work like digital cameras dispensing with the need for film to tomography that allows 3D X-ray pictures of the body to be created, computer technology has revolutionised the way we doctors peer into our bodies.
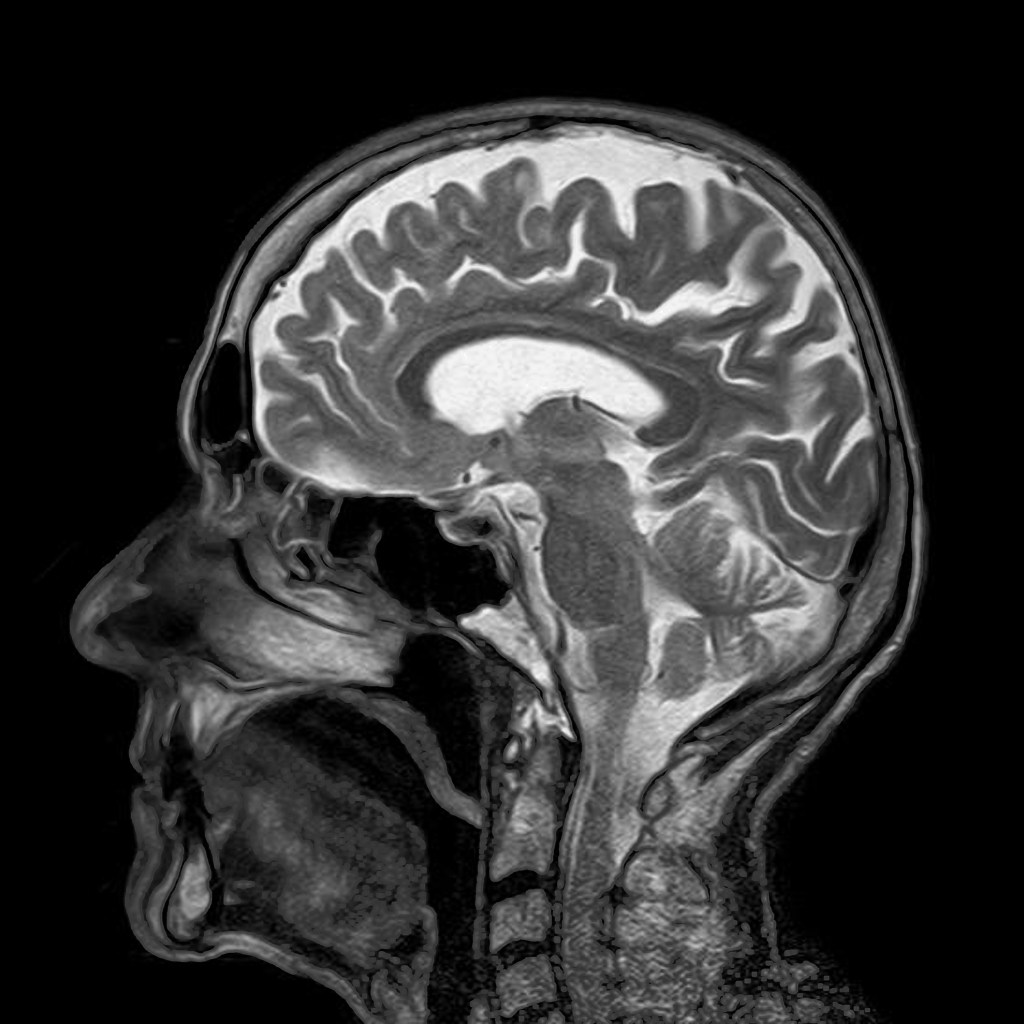
One of the most exciting ways to use computers to look into our bodies is called magnetic resonance imaging (MRI). While X-rays are very useful they only work when dense materials in the body absorb the X-rays energy (this loss of energy as they pass through the body is called attenuation). But lots of interesting stuff in our innards isn’t dense or filled with attenuating materials. We are after all flesh and blood, and those don’t show up on X-rays. Enter the magnet, or to be precise the proton. Water makes up the majority of structures in our body, and water has an interesting property. In a high magnetic field the protons in the hydrogen act like atomic magnets, and line up with (align with) the applied external magnetic field, like soldiers all standing to attention.
Wobbly Protons
We can then apply a radio wave; this radio wave has a magnetic element to it (that’s why it’s called an electromagnetic wave), and if we apply the radio wave with just the right frequency those aligned protons start to wobble. It’s like pushing a kid on a swing. If you keep pushing at the right time during the swing they will go higher and higher. It’s called resonance. Similarly if we hit the protons with the correct resonant frequency they start to spin round and round and round, and fall over. Take away the radio wave and the protons start to align themselves with the magnetic field again, like soldiers trying to regain their dignity, but as they do they give off energy in the form of a radio wave that we can pick up and measure.
Back to attention
Now rather than put the same magnetic field over all the protons we put a slope on the field, a gradient, with different magnetic fields in different places. Each proton then has its own little magnetic environment, and so its own resonant frequency. Now since we know what the magnetic field is at different places (as we put the slope on) we can fire the right radio wave frequency to unbalance only protons in certain places. After the pulse, as these protons try to realign, the strength of the signal they give out is in proportion to the number of protons in that area. In effect we can measure the amount of water in a particular area.
Magnets in the body
So how does this let us image inside bodies? In an MRI (Magnetic Resonance Image) scanner we have a big external magnetic field, and on top of this we add a smaller magnetic gradient across the body. That means each location across the body has a different local magnetic field. We then apply a radio pulse, at a range of resonant frequencies, and for each pulse we measure how much signal we get back. From this we can reconstruct an image of the water (proton) distribution across the body. We can also use tomographic techniques: by simply rotating the magnetic gradient around the body, we produce a 3D slice. The water content is different in different body tissues, so the scan shows us all the soft interesting stuff, where it is and what shape it’s in. Better still the way that the protons realign after they have been toppled is dependant on the chemicals round them, so we can even get some data on that too by looking at the speed at which they realign and give off their energy.
Blood in the brain
Blood contains a great deal of water, and blood that is oxygenated (contains oxygen) has different magnetic properties to blood that is deoxygenated. So by looking at where blood is giving up its oxygen we can see for example which parts of the brain are active when you look at colours, or listen to sounds. This is called functional imaging or fMRI, and through the wonders of computers and new algorithms we can now see not just structure inside the body, but also how it is working.
Ariana Grande, has added something new to her sell out stadium tours. She is controlling her vocals using gloves. Yep, gloves! To add reverb to her voice, Ariana pinches her thumb and forefinger. She changes background sounds by a sweep of the hand.
Imogen Heap, a Grammy award winning UK recording artist with a passion for technology, is behind the gesture control gloves that Florida born pop diva Ariana is wowing audiences across the world with.
Using technology to augment and change vocals is not new, sound engineers with banks of buttons and sliders have manipulated and improved performances for years, but now the artist can do it for themselves, using wearable tech with with bluetooth to control their sounds live.
So puff out your chest, robin and hear the humans notch up the sound gymnastics, we are not just limited to our vocal cords. Have a go at making wearables that control sound yourself. Maybe try Sonic Pi with a BBC micro:bit and search for the BBC’s ‘Strictly micro:bit live lesson’ for more on making your own wearable tech.
Google’s Fitbit is a smart wristwatch which doesn’t just tell you the time but can also monitor your movements and your heart beat. A particular time of day when your heart beat slows down and you move much less is at night when you’re fast asleep in bed.
Not everyone sleeps well though. Some people struggle to get to sleep and then wake up often during the night and so they feel tired during the day. The FitBit’s “Sleep Profiles” is an AI-supported sleep tracking tool (available to Premium subscribers) that may be able to help them. If the sleeper regularly wears their watch in bed it can monitor their sleep and build up a picture of how long it takes them to fall asleep, how often they wake up and offer some suggestions on how to get a better night’s rest.
So far Google has analysed 22 billion hours of sleep data from Fitbit users (who all agree to share their information so that they and everyone else can benefit from that shared knowledge). They used unsupervised machine learning to find out more about the data. This method gives an artificial intelligence lots of information but doesn’t tell it what to do with it. Instead they asked the AI to cluster groups of data together for the scientists to analyse and interpret. The result was six clusters of data showing the most common different ways that people sleep.
To make it easy for users to understand what the data meant, and how closely their own sleep pattern matched one of the clusters, Fitbit named each cluster after an animal. They took a bit of care over selecting animals to use as they wanted people to have more positive associations (no one wants to be called a sloth for example!) and came up with bear 🐻 tortoise 🐢dolphin 🐬giraffe 🦒parrot 🦜and hedgehog 🦔. People’s ‘sleep animals’ don’t stay the same though (just like our sleep) and you might be a dolphin one month and a tortoise the next. Tortoise-sleepers spend longer in bed but also take longer to fall asleep, and dolphin-sleepers sleep very lightly and tend to spend more time awake in bed.
Elena Perez, one of the product managers for Fitbit, said that parents of little children had told her that they’d seen the icon of the sleeping animal appear on their parents’ watch and knew that it was time to go to bed. Sweet dreams…
Did you know?
Dolphins and many birds use ‘unihemispheric sleep’ which means that one half of their brain (like humans their brains are also divided into two hemispheres) falls asleep first and the other stays awake. Then the hemispheres swap over!
In November, 2025, this catchy new country music song received lots of media attention. There’s nothing very unusual about that but what made this song unusual was that the whole thing (the words, the tune, even the singer) was created entirely by an artificial intelligence. There is no ‘Breaking Rust’, it’s all computer-generated. Now that you know that, does it make a difference to what you think of the song?
Lots of people are uneasy about a piece of music that had almost no direct human input into its creation. Music is a creative thing, designed and created by people and it feels unsettling to have computers doing that: for many it feels a bit like cheating. This song sounds human but if you listen carefully the singer seems to be performing the super-human feat of singing long stretches of the tune without taking a breath! A computer can do that, but people need oxygen!
And what is the future, if we are happy to listen to machine created things, that can be cheaply generated? Far less work, so livelihood, for human creatives. This is already happening in the world of the illustrator where it is harder than ever for newly graduated illustrators to get a foot on the ladder. Is that what we want for song writers and musicians too? Eventually, even the people running the programs to initiate the creation won’t be needed. If you want to listen to a new country song, or a new band, you will be able to click a button (pay some cash) and get one tailored for you. The money will go direct to a tech billionaire, of course.
Another thing people are very uneasy about is how the AI learned to write in that style of music in the first place. Music AI tools have been trained on vast amounts of other people’s music and, not surprisingly, many of those musicians are angry that their hard work has been re-used without permission or payment. Some musicians and music companies are now fighting back. They’ve asked lawyers to help them work with the AI companies so that they won’t lose out – they can instead opt in to allow their music be used to train AI tools, and this time they’ll be paid. This is basically what happens when musicians use the ideas of other musicians. Famously, “I’ll Be Missing You” by American rapper Puff Daddy and American singer Faith Evans, for example, used a sample without asking from the Police song, “Every Breath You Take”. Sting sued and as a result gets all the royalties from the song (though then had similar disputes with the other members of the Police!
A share of royalties might be a win for some of the musicians, and for the people who own the AI tools… but it still doesn’t solve how we might feel about AI music created by machines, or for future human musicians who might never get a break because new song writers can’t get a foot in the door. If you value people, you need to show it in what you watch, read and listen to!
Jo Brodie and Paul Curzon, Queen Mary University of London
The article above was inspired by BBC Tech Life’s 2nd December 2025 episode which had a 12min segment on AI-generated music. You can listen to the programme at https://www.bbc.co.uk/sounds/play/w3ct6zps [EXTERNAL]
Our new magazine, which you can also read online, on Music and AI
The Music and AI pages are sponsored by the EPSRC (UKRI3024: DA EPSRC university doctoral landscape award additional funding 2025 – Queen Mary University of London).
Subscribe to be notified whenever we publish a new post to the CS4FN blog.
Answers are at the bottom of https://cs4fn.blog/bitof6 where you can also read a copy of the magazine articles about Music and Artificial Intelligence.
Clues
1. _ _ _ _ _ a piece of text with musical symbols instead of letters that tells a performer which notes to play, also a piece of music that accompanies a film (5 letters)
2. and 10. _ _ _ _ _ _ (6 letters) separation is when computer scientists use AI to take a piece of music and split it into its _ _ _ _ _ (5 letters) – read more about this in ‘Separate your stems‘
3. The _ _ _ _ _ _ is the main part of the tune you might sing along to (6 letters)
4. A piece of music is made up of lots of different _ _ _ _ _ (5 letters)
5. We measure how loud something is in _ _ _ _ _ _ _ _ (8 letters)
6. A sequence of instructions that tell a computer what to do _ _ _ _ _ _ _ _ _ (9 letters)
7. If you halve the length of a guitar string the note is an _ _ _ _ _ _ (6 letters)
8. A guitar-like harp-lute from Ghana _ _ _ _ _ _ _ _ (8 letters) – read more about this in ‘The day the music didn’t die‘
9. How high or how low a musical note is _ _ _ _ _ (5 letters)
The Music and AI pages are sponsored by the EPSRC (UKRI3024: DA EPSRC university doctoral landscape award additional funding 2025 – Queen Mary University of London).
Subscribe to be notified whenever we publish a new post to the CS4FN blog.