Bayesian networks give a foundation for tools that support decision making based on evidence collected and the probabilities of one thing causing another (see “What are the chances of that?“).
The first algorithms that enabled Bayesian network models to be calculated on a computer were discovered separately by two different research groups in the late 1980s. Since then, a series of easy-to-use software packages have been developed that implement these algorithms, so that people without any knowledge of computing or statistics can easily build and run their own models.
These algorithms do ‘exact’ computations and can handle Bayesian networks for many different types of problems, but they can run into a barrier: when run on Bayesian networks beyond a certain size or complexity, they take too long to compute even on the world’s fastest computers. However, newer algorithms – which provide good approximate calculations rather than exact ones – have made it possible to deal with much larger problems, and this is a really exciting ongoing research area.
Norman Fenton, Queen Mary University of London, Spring 2021
In the film Minority Report, a team of psychics – who can see into the future – predict who might cause harm, allowing the police to intervene before the harm happens. It is science fiction. But smart technology is able to see into the future. It may be able to warn months in advance when a mother’s body might be about to harm her unborn baby and so allow the harm to be prevented before it even happens.
Gestational diabetes (or GDM) is a type of diabetes that appears only during pregnancy. Once the baby is born it usually disappears. Although it doesn’t tend to produce many symptoms it can increase the risk of complications in pregnancy so pregnant women are tested for it to avoid problems. Women who’ve had GDM are also at greater risk of developing Type 2 diabetes later on, joining an estimated 4 million people who have the condition in the UK.
Diabetes happens either when someone’s pancreas is unable to produce enough of a chemical called insulin, or because the body stops responding to the insulin that is produced. We need insulin to help us make use of glucose: a kind of sugar in our food that gives us energy. In Type 1 diabetes (commonly diagnosed in young people) the pancreas pretty much stops producing any insulin. In Type 2 diabetes (more commonly diagnosed in older people) the problem isn’t so much the pancreas (in fact in many cases it produces even more insulin), it’s that the person has become resistant to insulin. The result from either ‘not enough insulin’ or ‘plenty of insulin but can’t use it properly’ is that glucose isn’t able to get into our cells to fuel them. It’s a bit like being unable to open the fuel cap on a car, so the driver can’t fill it with petrol. This means higher levels of glucose circulate in the bloodstream and, unfortunately, high glucose can cause lots of damage to blood vessels.
During a normal pregnancy, women often become a little more insulin-resistant than usual anyway. This is an effect of pregnancy hormones from the placenta. From the point of view of the developing foetus, which is sharing a blood supply with mum, this is mostly good news as the blood arriving in the placenta is full of glucose to help the baby grow. That sounds great but if the woman becomes too insulin-resistant and there’s too much glucose in her blood it can lead to accelerated growth (a very large baby) and increase the risk of complications during pregnancy and at birth. Not great for mum or baby. Doctors regularly monitor the blood glucose levels in a GDM pregnancy to keep both mother and baby in good health. Once taught, anyone can measure their own blood glucose levels using a finger-prick test and people with diabetes do this several times a day.It will save money but also be much more flexible for mothers.
In-depth screening of every pregnant woman, to see if she has, or is at risk of, GDM costs money and is time-consuming, and most pregnant women will not develop GDM anyway. PAMBAYESIAN researchers at Queen Mary have developed a prototype intelligent decision-making tool, both to help doctors decide who needs further investigation, but also to help the women decide when they need additional support from their healthcare team.
The team of computer scientists and maternity experts developed a Bayesian network with information based on expert knowledge about GDM, then trained it on real (anonymised) patient data. They are now evaluating its performance and refining it. There are different decision points throughout a GDM pregnancy. First, does the person have GDM or are they at increased risk (perhaps because of a family history)? If ‘yes’ then the next decision is how best to care for them and whether or not to begin medical treatment or just give diet and lifestyle support. Later on in the pregnancy the woman and her doctor must consider when it’s best for her to deliver her baby, then later she needs ongoing support to prevent her GDM from leading to Type 2 diabetes. Currently in early development work, it’s hoped that if given blood glucose readings, the GDM Bayesian network will ultimately be able to take account of the woman’s risk factors (like age, ethnicity and previous GDM) that increase her risk. It would use that information to predict how likely she is to develop the condition in this pregnancy, and suggest what should happen next.
Systems like this mean that one day your smartphone may be smart enough to help protect you and your unborn baby from future harm.
Jo Brodie, Queen Mary University of London, Spring 2021
Thomas Bayes is famous for the theorem named after him: Bayes’ theorem. (See What are the chances of that?) It can be used in any situation where we want to calculate a more accurate probability of something given extra evidence. We will look at a version for our virus problem from there. For a graphical version of what this algorithm is doing see A graphical explanation of Bayes’ theorem
We want to know the probability that you have the virus (called the “posterior probability”), given that have you just tested positive. In that case Bayes’ theorem becomes:
The theorem tells us that the chance that a person who tests positive actually has the virus is just the number of people with the virus who test positive divided by the total number of people (with or without the virus) who test positive.
The theorem can be used as the basis of an algorithm to compute the new, more accurate probability that we are after. We will assume, to make things easier to follow, that we are considering a population of a thousand people. We get the following algorithm:
To calculate accurate probability that you have the virus after testing positive:
STEP 1: Calculate how many people BOTH have the virus AND test positive.
STEP 2: Calculate the number of people who will test positive (whether they have the virus or not).
STEP 3: Divide ANSWER 1) by ANSWER 2) to give the final answer of the probability you have the virus after testing positive.
Let’s work through it with the numbers from our example. Stay calm! This is going to get hairy if you are not a computer!
What do we know? Well, actually we need another little algorithm to do Step 1:
To calculate how many people BOTH have the virus AND test positive (answer to step 1):
STEP 1a: Calculate the probability that you will test positive if you do have the virus.
STEP 1b: Calculate the probability you have the virus BEFORE knowing the test result.
STEP 1c: Multiply ANSWER 1a by ANSWER 1b by 1000 (our population).
This calculates the answer to Step 1 for us. We have said we have a test that is always positive if you do have the virus (in reality tests do get it wrong this way too but, to keep things simple, we will ignore that here). That means the answer needed for Step 1a is a probability of 1 (meaning it is 100 per cent certain that it gets the answer right if you have the virus).
What about Step 1b? That is the country-wide probability of having the virus we are starting with. Knowing nothing else about an individual we have said 1 in 200 people have the virus. That makes the answer needed for this step: 1 / 200, so probability, 0.005
We can now calculate Step 1c: We just multiply those two numbers 1 x 0.005 and multiply that by the total number of people: 1000. This gives the answer that five people out of the 1000 have the virus and test positive.
Step 2 is a bit more tricky: it is the number of people out of our 1000 who test positive. That includes all those with the virus but ALSO those that the test wrongly says have the virus when they don’t. We need to add the numbers for these two groups: those with the virus and those without.
To calculate the number of people who test positive (answer to step 2):
STEP 2a: Calculate the number of people who have the virus AND who test positive (This is just the answer from Step 1.)
STEP 2b: Calculate the number of people who do NOT have the virus AND who test positive.
STEP 2c: Add ANSWER 2a and ANSWER 2b together.
We have already worked out the first part (Step 2a). It is just the answer from Step 1, so we already know it is five people. Step 2b is calculated in a similar way to Step 1 as follows:
To calculate the number of people who do not have the virus AND who test positive (answer to step 2b):
STEP 2bi: Calculate the probability that you will test positive if you do NOT have the virus.
STEP 2bii: Calculate the probability you do not have the virus.
STEP 2biii: Multiple ANSWER 2bi by ANSWER 2bii and then by 1000 to give the number of people who do not have the virus but test positive.
We know the answer to Step 2bi, as we said there was a two per cent chance of the test telling you that you had the virus when you didn’t. That means the answer to this step is 2 / 100 = 0.02.
For Step 2bii, the probability a person does NOT have the virus, we just need to calculate the rest of the population excluding those with the virus. We said one in every 200 people have the virus. That means 199 in 200 do not have it. The answer to this step is therefore 199 / 200 = 0.995.
So, to work out Step 2biii to find out the number of people who do not have the virus but test positive: we multiply our two above answers 0.02 x 0.995, then multiply this by 1000. This gives answer 19.9: so about 20 out of the 1000 people are incorrectly told they have the virus.
We can now go back to Step 2c and add the answer from Step 2a (of those correctly told they have the virus) to that from Step 2b (those told they have the virus when they do not). This is 5 + 20, so 25 people in total are given a positive result. This is the answer to Step 2.
Finally, we can work out the overall, more accurate probability (Step 3). Divide the answer from Step 1, (five people), by the answer to Step 2 (25 people), to give the final probability as 5 / 25 = 0.2 or a 20 per cent chance you actually have the virus after testing positive.
Don’t forget we have just made up the numbers here to show the maths. Although no test is 100 per cent accurate, the current Covid tests can be confirmed with an additional test to give further evidence.
Norman Fenton and Paul Curzon, Queen Mary University of London, Spring 2021
Computer tools based on what are called “Bayesian networks” give accurate ways to determine how likely things are. For example, they give a good way, based on evidence, to determine how likely a given person has COVID. As you collect more evidence, the probability the network gives becomes more accurate.
How likely is it that you have COVID? There is lots of evidence you might collect to decide whether or not you do. It causes many (but not all) people to cough. So if you do have the a cough that is useful evidence. Other things like flu, however, also cause people to cough. Catching COVID is also known to be caused by breathing the same air as infected people. The more socialising you have done the higher the chance you have caught it, but also the more people in your area with the disease the more likely it is that you have caught it by socialising. You can also take a test – having COVID will cause a positive result. However, tests are not fully accurate, so even with a positive test you may or may not have COVID…
Deciding how likely it is you have COVID relies on knowing lots of facts about the causes of COVID and about the symptoms it causes. It also relies on knowing the probabilities of things such as how likely it is that COVID causes a cough. Finally it relies on knowing lots of facts about you such as whether you have had a positive test result or not.
A Bayesian network is just a way of drawing a diagram that collects all this information in one place. Once created it can be used to determine how likely things like whether you have COVID are to be true based on known facts, known causes, and the chances of one thing causing another. It gives a powerful way to reason about these facts and probabilities based on “causal relationships”. That reasoning allows accurate probabilities to be calculated about the things you are interested in knowing. Given I have a cough and no other symptoms, have had a negative test but have recently socialised outside my family, am I 80 per cent certain I have COVID or is the chance I have it only 2 per cent?
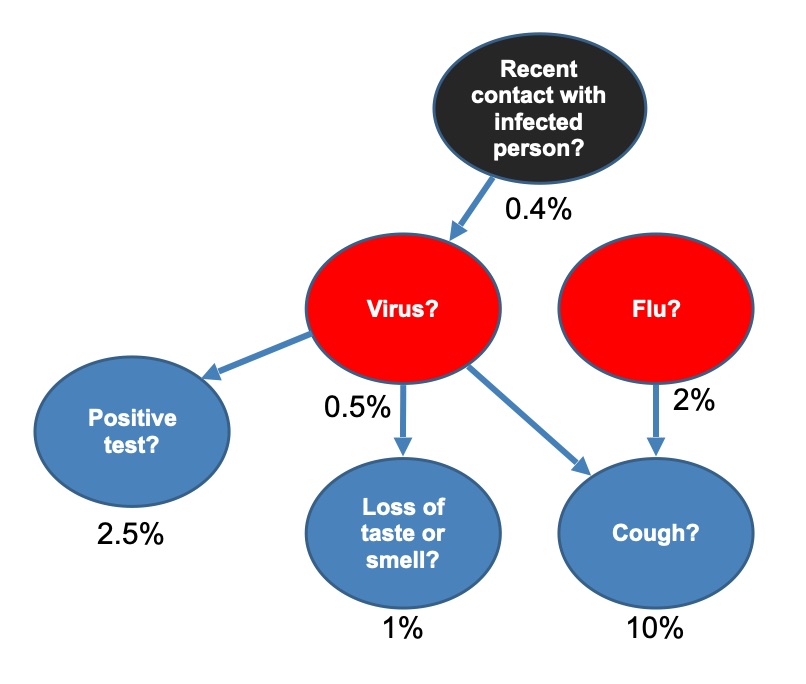
We can take all the evidence for and against our having the virus and draw a Bayesian network as shown in the diagram. For each bubble the percentages show the chance that for a random person in the population this thing is currently true. Arrows show which things can cause others. So, in the diagram, this means that 0.5 per cent of the population currently have the virus (as 1 in 200 have the virus, so probability 0.005, and to turn a probability into a percentage you just multiply by 100); 0.4 per cent of the population have been in recent contact with an infected person; 10 per cent have a cough; 2 per cent have flu, and so on. This is all general evidence we can collect about the country as a whole. (Note we have made up these numbers for the example as they may change over time, but they are the kinds of data scientists collect to help policy makers make decisions.)
The model also includes probabilities not shown, like the chance of a person getting the virus if they have been in recent contact with an infected person and the probability of a positive test depending on whether they do, or do not, have the virus. Once a particular Bayesian network like this has been created it can form the basis of a decision making tool that does all the calculations.
We then want to know about you. Do you have a cough, have you lost your sense of taste or smell, what was the result of your test, and have you been in contact with an infected relative? From this information, we can update the probabilities in the Bayesian network (using a theorem called Bayes’ theorem) to give a new probability for how likely it is that you have the virus. Computer software can do this for us, though the more complicated the Bayesian network, the longer it takes to do all the calculations.
The result, though, is that the computer can give you a personalised risk assessment of how likely it is that you have the virus based on the specific evidence about you. You can find such a comprehensive personal COVID risk calculator, based on a Bayesian network with much more data, at covid19.apps.agenarisk.com/
Norman Fenton andPaul Curzon, Queen Mary University of London, Spring 2021
Graphic by Paul Curzon based on a graphical proof of Norman Fenton
If you take a test how do you work out how likely it is that you have the virus? Bayesian reasoning is one way (see “What are the chances of that”). Here is a graphical version of what that kind of reasoning is actually about.
If recent data shows that the virus currently affects one in 200 of the population, then it is reasonable to start with the assumption that the probability YOU have the virus is one in 200 (we call this the ‘prior probability’). Another way of saying that is that the prior probability is 0.5 per cent.
A better estimate
Suppose the probability a random person has the virus is 1 in 200 or 0.5 per cent. With no other evidence, your best guess that you have the virus is then also 0.5 per cent. You have also however taken a test and it was positive. However, for every 100 people taking the test, 2 will test positive when they actually do NOT have the virus. This means that the false positive rate is 2 per cent.
How? Bayes worked out a general equation for calculating this new, more accurate probability, called the ‘posterior’ probability (see page 8). It is based, here, on the probability of having the virus before testing (the original, prior probability) and any new evidence, which here is the test result.
A surprising result
How likely is it that you have the virus? With only this evidence, the probability you have the virus is still only 20 per cent.
Norman Fenton, Queen Mary University of London, Spring 2021
The hobby of a church minister over 250 years ago is helping computers make clever decisions.
Thomas Bayes was an English church minister who died in 1761. His hobby was a type of maths that today we call probability and statistics, though his writings were never really recognised during his own lifetime. So, how is the hobby of this 18th century church minister driving computers to become smarter than ever? His work is now being used in applications as varied as: helping to diagnose and treat various diseases; deciding whether a suspect’s DNA was at a crime scene; accurately recommending which books and films we will like; setting insurance premiums for rare events; filtering out spam emails; and more.
How likely is that?
Bayes was interested in calculating how likely things were to happen (their probability) and particularly things that cannot be observed directly. Suppose, for example, you want to know the probability that you have an infectious virus, something you can’t just tell by looking. Perhaps you’re going to a concert of your favourite band – one for which you’ve already paid a lot of money. So you need to know you are not infected. If recent data shows that the virus currently affects one in 200 of the population, then it is reasonable to start with the assumption that the probability YOU have the virus is one in 200 (we call this the ‘prior probability’). Another way of saying that is that the prior probability is 0.5 per cent.
A better estimate
However, you can get a much better estimate of how likely it is that you have the virus if you can gather more evidence of your personal situation. With a virus you can get tested. If the test was always correct, then you would know for certain. Tests are never perfect though. Let’s suppose that for every 100 people taking the test, two will test positive when they actually do NOT have the virus. Scientists call this the false positive rate: here two per cent. You take the test and it is positive. You can use this information to get a better idea of the likelihood you have the virus.
How? Bayes worked out a general equation for calculating this new, more accurate probability, called the ‘posterior’ probability. It is based, here, on the probability of having the virus before testing (the original, prior probability) and any new evidence, which here is the test result.
A surprising result
If we assume in our example that every person who does have the virus is certain to test positive then, plugging the numbers into Bayes’ theorem, tells us there is actually a surprisingly low, one in five (i.e., 20 per cent) chance you have the virus after testing positive. See A Graphical Explanation of Bayes’ theorem for why the answer is correct. Although this is much higher than the probability of having the virus without testing (two per cent), it still means you are unlikely to have the virus despite the positive test result!
If you understand Bayes theorem, you might feel it unfair if your doctor still insists that you have the virus and must miss the trip. In fact, many people find the result very surprising; generally, doctors who do not know Bayes’ theorem massively overestimate the likelihood that patients have a disease after a positive test result. But that is why Bayes’ theorem is so important.
To go or not to go
Of course, no one knows which are the five concert goers that are the ones infected. If all 25 ignore their doctor that means there are five people mingling in the crowd, passing on the virus, which would mean lots more people catch the virus who pass it on to lots more, who … (see Ping pong vaccination).
We have seen that, with a little extra information (such as a test result), we can work out a more accurate probability and so have better information upon which to make decisions. In practice, there are many different kinds of information that we can use to improve our estimate of the real probability. There are symptoms such as lack of taste/smell which are quite specific to the virus. Others, like a cough, are common in people with the virus but also in people with flu. There are also factors that can cause a person to have the virus in the first place such as close contact with an infected relative. So, instead of just inferring the probability of having the virus from one piece of information, like the test result, we can consider lots of interconnected data, each with its own prior probability. This is where computers come in: to do all the calculations for us.
We first need to tell the computer about what causes what. A convenient way to do this is to draw a diagram of the connections and probabilities called a ‘Bayesian network’ (see A Simple Bayesian Network – to come). Once a computer has been given the Bayesian network, it can not only work out more accurate probabilities, but it can also use them to start making decisions for us. This is where all those applications come in. Deciding whether a suspect’s DNA was at a crime scene, for example, needs the same kind of reasoning as deciding whether you have the virus.
Obviously, it is more complex to apply Bayes’ theorem in realistic situations and, until quite recently, even the fastest computers weren’t able to do the calculations. However, breakthroughs by computer scientists developing new algorithms mean that very complex Bayesian networks, with lots of inter-connected causes, can now be computed efficiently. Because of this, Bayesian networks can now be applied to a multitude of important problems that were previously impossible to solve. And that is why, perhaps surprisingly, the ideas of Thomas Bayes, from over 250 years ago, are showing us how to build machines that make smarter decisions when things are uncertain.
Norman Fenton, Queen Mary University of London, Spring 2021
The trouble with healthcare is that it’s becoming ever more expensive: new drugs, new treatments, more patients, the ever-increasing time needed with experts. Smart healthcare might be able to help.
We want everyone to get the care they need, but the costs are growing. Perhaps computer scientists can help? Research groups worldwide are exploring ways to create computing technology to improve healthcare, and intelligent programs that can support patients at home, helping monitor them and make decisions about what to do.
For example, say you are on powerful drugs to manage a long term illness: should you have the vaccine? Can you have a baby? Is a flare up of your disease about to hit you and how can you avoid it? Is that new ache a side effect of the drugs? Do you need to change medicines? Do you need to see a specialist?
If smart programs can help support patients then the doctors and nurses can spend more time with those who actually need it, hospitals can save on expensive drugs that aren’t working, and patients can have better lives. But what kind of technology can deliver this sort of service?
In the current issue of cs4fn magazine, we explore one particular way being developed on the EPSRC funded PAMBAYESIAN project at Queen Mary University of London, based on an area of computing called Bayesian networks, that might just be the answer. We also look at other ways computers can help deliver better healthcare for all and other uses of Bayesian networks.