Continuing a series of blogs on what to do with all that lego scattered over the floor: learn some computer science…what does number representation mean?
We’ve seen some different ways to represent images and how ultimately they can be represented as numbers but how about numbers themselves. We talk as though computers can store numbers as numbers but even they are represented in terms of simpler things in computers.
But first what do we mean by a number and a representation of a number? If I told you to make the numbers 0 to 9 in lego (go on have a go) you may well make something like this…
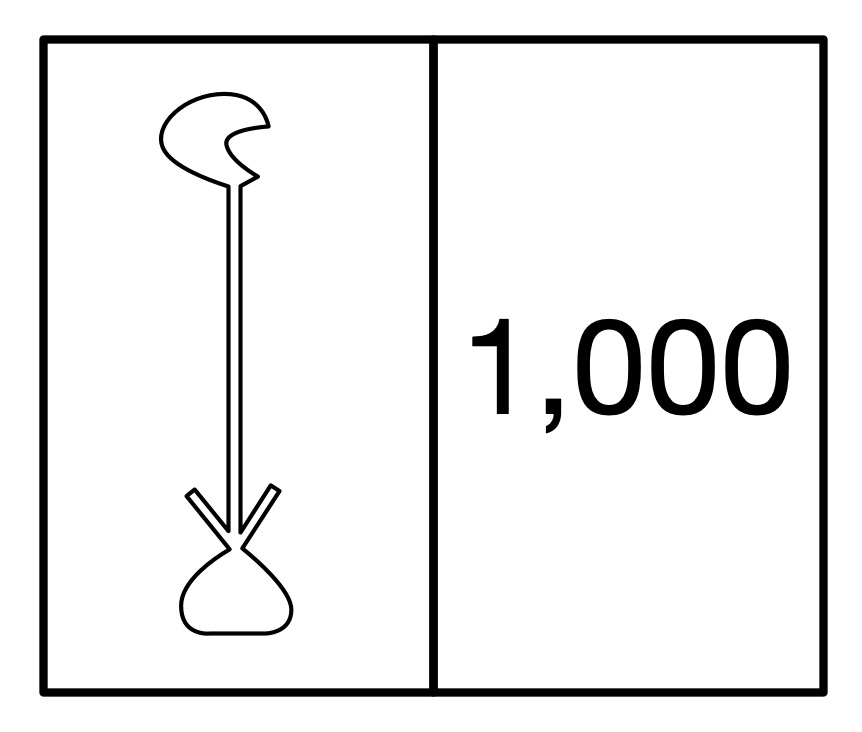
But those symbols 0, 1, 2, … are just that. They are symbols representing numbers not the numbers themselves. They are arbitrary choices. Different cultures past and present use different symbols to mean the same thing. For example, the ancient Egyptian way of writing the number 1000 was a hieroglyph of a water lily. (Perhaps you can make that in lego!)
What really are numbers? What is the symbol 2 standing for? It represents the abstract idea of twoness ie any collection, group or pile of two things: 2 pieces of lego, 2 ducks, 2 sprouts, … and what is twoness? … it is oneness with one more thing added to the pile. So if you want to get closer to the actual numbers then a closer representation using lego might be a single brick, two bricks, three bricks, … put together in any way you like.
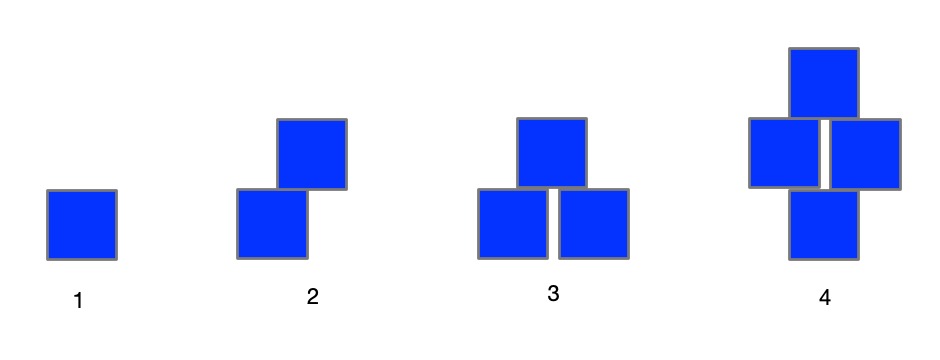
Image by CS4FN
Another way would to use different sizes of bricks for them. Use a lego brick with a single stud for 1, a 2-stud brick for two and so on (combining bricks where you don’t have a single piece with the right number of studs). In these versions 0 is the absence of anything just like the real zero.
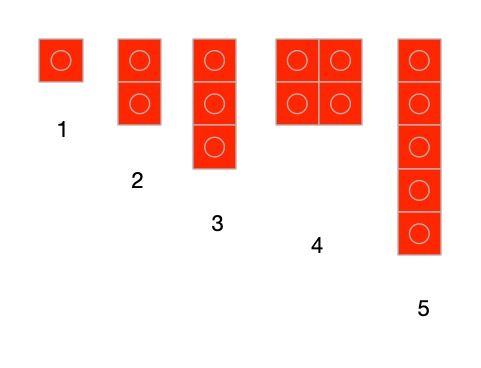
Image by CS4FN
Once we do it in bricks it is just another representation though – a symbol of the actual thing. You can actually use any symbols as long as you decide the meaning in advance, there doesn’t actually have to be any element of twoness in the symbol for two. What other ways can you think of representing numbers 0 to 9 in lego? Make them…
A more abstract set of symbols would be to use different coloured bricks – red for 1, blue for 2 and so on. Now 0 can have a direct symbol like a black brick. Now as long as it is the right colour any brick would do. Any sized red brick can still mean 1 (if we want it to). Notice we are now doing the opposite of what we did with images. Instead of representing a colour with a number, we are representing a number with a colour.

Image by CS4FN
Here is a different representation. A one stud brick means 1, a 2-stud brick means 2, a square 4 stud brick means 3, a rectangular 6 stud brick means 4 and so on. As long as we agreed that is what they mean it is fine. Whatever representation we choose it is just a convention that we have to then be consistent about and agree with others.
Image by CS4FN
What has this to do with computing? Well if we are going to write algorithms to work with numbers, we need a way to store and so represent numbers. More fundamentally though, computation (and so at its core computer science) really is all about symbol manipulation. That is what computational devices (like computers) do. They just manipulate symbols using algorithms. We will see this more clearly when we get to creating a simple computer (a Turing Machine) out of lego (but that is for later).
We interpret the symbols in the inputs of computers and the symbols in the outputs with meanings and as a result they tell us things we wanted to know. So if we key the symbols 12+13= into a calculator or computer and it gives us back 25, what has happened is just that it has followed some rules (an algorithm for addition) that manipulated those input symbols and made it spew out the output symbols. It has no idea what they mean as it is just blindly following its rules about how to manipulate symbols. We also could have used absolutely any symbols for the numbers and operators as long as they were the ones the computer was programmed to manipulate. We are the ones that add the intelligence and give those symbols meanings of numbers and addition and the result of doing an addition.
This is why representations are important – we need to choose a representation for things that makes the symbol manipulation we intend to do easy. We already saw this with images. If we want to send a large image to someone else then a representation of images like run-length encoding that shrinks the amount of data is a good idea.
When designing computers we need to provide them with a representation of numbers so they can manipulate those numbers. We have seen that there are lots of representations we could choose for numbers and any in theory would do, but when we choose a representation of numbers for use to do computation, we want to pick one that makes the operations we are interested in doing easy. Charles Babbage for example chose to use cog-like wheels turned to particular positions to represent numbers as he had worked out how to create a mechanism to do calculation with them. But that is something for another time…
Paul Curzon, Queen Mary University of London
More on …
- Lego Computer Science
- Part of a series featuring featuring pixel puzzles,
compression algorithms, number representation,
gray code, binary and computation.
- Part of a series featuring featuring pixel puzzles,
Subscribe to be notified whenever we publish a new post to the CS4FN blog.
This blog is funded by EPSRC on research agreement EP/W033615/1.

This post was funded by UKRI, through grant EP/K040251/2 held by Professor Ursula Martin, and forms part of a broader project on the development and impact of computing.