Most people in hospital get great treatment but if something does go wrong the victims often want something good to come of it. They want to understand why it happened and be sure it won’t happen to anyone else. Medical mistakes can make a big news story though with screaming headlines vilifying those ‘responsible’. It may sell papers but it could also make things worse.
If press and politicians are pressurising hospitals to show they have done something, they may only sack the person who made the mistake. They may then not improve things meaning the same thing could happen again if it was an accident waiting to happen. Worse if we’re too quick to blame and punish someone, other people will be reluctant to report their mistakes, and without that sharing we can’t learn from them. One of the reasons flying is so safe is that pilots always report ‘near misses’ knowing they will be praised for doing so, rather than getting into trouble. It’s far better to learn from mistakes where nothing really bad happens than wait for a tragedy.
Share mistakes to learn from them
Chrystie Myketiak from Queen Mary explored whether the way a medical technology story is reported makes a difference to how we think about it, and ultimately what happens. She analysed news stories about three similar incidents in the UK, America and Canada. She wanted to see what the papers said, but also how they said it. The press often sensationalise stories but Chrystie found that this didn’t always happen. Some news stories did imply that the person who’d made the mistake was the problem (it’s rarely that simple!) but others were more careful to highlight that they were busy people working under stressful conditions and that the mistakes only happened because there were other problems. Regulations in Canada mean the media can’t report on specific details of a story while it is being investigated. Chrystie found that, in the incidents she looked at, that led to much more reasoned reporting. In that kind of environment hospitals are more likely to improve rather than just blame staff. How the hospital handled a case also affected what was written – being open and honest about a problem is better than ignoring requests for comment and pretending there isn’t a problem.
Everyone makes mistakes (if you don’t believe that, the next time you’re at a magic show, make sure none of the tricks fool you!). Often mistakes happen because the system wasn’t able to prevent them. Rather than blame, retrain or sack someone its far better to improve the system. That way something good will come of tragedies.
– Paul Curzon, Queen Mary University of London (From the archive)
Ada Lovelace, the ‘first programmer’ thought the possibilities of computer science might cover a far wider breadth than anyone else of her time. For example, she mused that one day we might be able to create mathematical models of the human nervous system, essentially describing how electrical signals move around the body. University of Oxford’s Blanca Rodriguez is interested in matters of the heart. She’s a bioengineer creating accurate computer models of human organs.
How do you model a heart? Well you first have to create a 3D model of its structure. You start with MRI scans. They give you a series of pictures of slices through the heart. To turn that into a 3D model takes some serious computer science: image processing that works out, from the pictures, what is tissue and what isn’t. Next you do something called mesh generation. That involves breaking up the model into smaller parts. What you get is more than just a picture of the surface of the organ but an accurate model of its internal structure.
So far so good, but it’s still just the structure. The heart is a working, beating thing not just a sculpture. To understand it you need to see how it works. Blanca and her team are interested in simulating the electrical activity in the heart – how electrical pulses move through it. To do this they create models of the way individual cells propagate an electrical system. Once you have this you can combine it with the model of the heart’s structure to give one of how it works. You essentially have a lot of equations. Solving the equations gives a simulation of how electrical signals propagate from cell to cell.
The models Blanca’s team have created are based on a healthy rabbit heart. Now they have it they can simulate it working and see if it corresponds to the results from lab experiments. If it does then that suggests their understanding of how cells work together is correct. When the results don’t match, then that is still good as it gives new questions to research. It would mean something about their initial understanding was wrong, so would drive new work to fix the problem and so the models.
Once the models have been validated in this way – shown it is an accurate description of the way a rabbit’s heart works – they can use them to explore things you just can’t do with experiments – exploring what happens when changes are made to the structure of the virtual heart or how drugs change the way it works, for example. That can lead to new drugs.
They can also use it to explore how the human heart works. For example, early work has looked at the heart’s response to an electric shock. Essentially the heart reboots! That’s why when someone’s heart stops in hospital, the emergency team give it a big electric shock to get it going again. The model predicts in detail what actually happens to the heart when that is done. One of the surprising things is it suggests that how well an electric shock works depends on the particular structure of the person’s heart! That might mean treatment could be more effective if tailored for the person.
Computer modelling is changing the way science is done. It doesn’t replace experiments. Instead clinical work, modelling and experiments combine to give us a much deeper understanding of the way the world, and that includes our own hearts, work.
Paul Curzon, Queen Mary University of London
The charity Cardiac Risk in the Young raises awareness of cardiac electrical rhythm abnormalities and supports testing (electrocardiograms and echocardiograms) for all young people aged 14-35.
Subscribe to be notified whenever we publish a new post to the CS4FN blog.
This blog is funded by EPSRC on research agreement EP/W033615/1.
In 2009 Desi Cryer, who is Black, shared a light-hearted video with a serious message. He’d bought a new computer with a face tracking camera… which didn’t track his face, at all. It did track his White colleague Wanda’s face though. In the video (below) he asked her to go in front of the camera and move from side to side and the camera obediently tracked her face – wherever she moved the camera followed. When Desi moved back in front of the camera it stopped again. He wondered if the computer might be racist…
Another video, this time from 2017, showed a dark-skinned man failing to get a soap to dispenser to give him some soap. Nothing happened when he put his hand underneath the sensor but as soon as his lighter-skinned friend put his hand under it – out popped some soap! The only way the first man could get any soap dispensed was to put a white tissue on his hand first. He wondered if the soap dispenser might be racist…
What’s going on?
Probably no-one set out to maliciously design a racist device but designers might need to check that their products work with a range of different people before putting them on the market. This can save the company embarrassment as well as creating something that more people want to buy.
Sensors working overtime
Both devices use a sensor that is activated (or in these cases isn’t) by a signal. Soap dispensers shine a beam of light which bounces off a hand placed below it and some of that light is reflected back. Paler skin reflects more light (and so triggers the sensor) than darker skin. Next to the light is a sensor which responds to the reflected light – but if the device was only tested on White people then the sensor wasn’t adjusted for the full range of skin tones and so won’t respond appropriately. Similarly cameras have historically been designed for White skin tones meaning darker tones are not picked up as well.
Things can be improved!
It’s a good idea, when designing something that will be used by lots of different people, to make sure that it will work correctly with everyone. Having a diverse design team and, importantly, making sure that everyone feels empowered to contribute is a good way to start. Another is to test the design with different target audiences early in the design process so that changes can be made before it’s too late. How a company responds to feedback when they’ve made an oversight is also important. In the case of the computer company they acknowledged the problem and went to work to improve the camera’s sensitivity.
During the coronavirus pandemic many people bought a ‘pulse oximeter’, a device which clips painlessly onto a finger and measures how much oxygen is circulating in your blood (and your pulse). If the oxygen reading became too low people were advised to go to hospital. Oximeters shine red and infrared light from the top clip through the finger and the light is absorbed diferently depending on how much oxygen is present in the blood. A sensor on the lower clip measures how much light has got through but the reading can be affected by skin colour (and coloured nail polish). People were concerned that pulse oximeters would overestimate the oxygen reading for someone with darker skin (that is, tell them they had more oxygen than they actually had) and that the devices might not detect a drop in oxygen quickly enough to warn them.
In response the UK Government announced in August 2022 that it would investigate this bias in a range of medical devices to ensure that future devices work effectively for everyone.
Inspired by Mary Shelley’s Frankenstein, 17-year old Victorian orphan, Jane Webb secured her future by writing the first ever Mummy story. The 22nd century world in which her novel was set is perhaps the most amazing thing about the three volume book though.
On the death of her father, Jane realised she needed to find a way to support herself and did so by publishing her novel “The Mummy!” in 1827. In contrast to their modern version as stars of horror films, Webb’s Mummy, a reanimation of Cheops, was actually there to help those doing good and punish those that were evil. Napoleon had, through the start of the century, invaded Egypt, taking with him scholars intent on understanding the Ancient Egyptian society. Europe was fascinated with Ancient Egypt and awash with Egyptian artefacts and stories around them. In London, the Egyptian Hall had been built in Piccadilly in 1812 to display Egyptian artefacts and in 1821 it displayed a replica of the tomb of Seti I. The Rosetta Stone that led to the decipherment of hieroglyphics was cracked in 1822. The time was therefore ripe for someone to come up with the idea of a Mummy story.
The novel was not, however, set in Victorian times but in a 22nd century future that she imagined, and that future was perhaps more amazing than the idea of a mummy coming to life. Her version of the future was full of technological inventions supporting humanity, as well as social predictions, many of which have come to fruition such as space travel and the idea that women might wear trousers as the height of fashion (making her a feminist hero). The machines she described in the book led to her meeting her future husband, John Loudon. As a writer about farming and gardening he was so impressed by the idea of a mechanical milking machine included in the book, that he asked to meet her. They married soon after (and she became Jane Loudon).
The skilled artificial intelligences she wrote into her future society are perhaps the most amazing of her ideas in that she was the first person to really envision in fiction a world where AIs and robots were embedded in society just doing good as standard. To put this into context of other predictions, Ada Lovelace wrote her notes suggesting machines of the future would be able to compose music 20 years later.
Jane Webb’s future was also full of cunning computational contraptions: there were steam-powered robot surgeons, foreseeing the modern robots that are able to do operations (and with their steady hands are better at, for example, eye surgery than a human). She also described Artificial Intelligences replacing lawyers. Her machines were fed their legal brief, giving them instructions about the case, through tubes. Whilst robots may not yet have fully replaced barristers and judges, artificial intelligence programs are already used, for example, to decide the length of sentences of those convicted in some places, and many see it now only being a matter of time before lawyers are spending their time working with Artificial Intelligence programs as standard. Jane’s world also includes a version of the Internet, at a time before electric telegraph existed and when telegraph messages were sent by semaphore between networks of towers.
The book ultimately secured her future as required, and whilst we do not yet have any real reanimated mummy’s wandering around doing good deeds, Jane Webb did envision lots of useful inventions, many that are now a reality, and certainly had pretty good ideas about how future computer technology would pan out in society…despite computers, never mind artificial intelligences, still being well over a century away.
Industrialist Tony Stark always dresses for the occasion, even when that particular occasion happens to be a fight with the powers of evil.His clothes are driven by computer science: the ultimate in wearable computing.
In the Iron Man comic and movie franchise Anthony Edward Stark, Tony to his friends, becomes his crime fighting alter ego by donning his high tech suit. The character was created by Marvel comic legend Stan Lee and first hit the pages in 1963. The back story tells how industrial armaments engineer and international playboy Stark is kidnapped and forced to work to develop new forms of weapons, but instead manages to escape by building a flying armoured suit.
Though the escape is successful Stark suffers a major heart injury during the kidnap ordeal, becoming dependant on technology to keep him alive. The experience forces him to reconsider his life, and the crime avenging Iron Man is born. Lee’s ‘businessman superhero’ has proved extremely popular and in recent years the Iron Man movies, starring Robert Downey Jr, have been box office hits. But as Tony himself would be the first to admit, there is more than a little computer science supporting Iron Man’s superhero standing.
Suits you
The Iron Man suit is an example of a powered exoskeleton. The technology surrounding the wearer amplifies the movement of the body, a little like a wearable robot. This area of research is often called ‘human performance augmentation’ and there are a number of organisations interested in it, including universities and, unsurprisingly, defence companies like Stark Industries. Their researchers are building real exoskeletons which have powers uncannily like those of the Iron Man suit.
To make the exoskeleton work the technology needs to be able to accurately read the exact movements of the wearer, then have the robot components duplicate them almost instantly. Creating this fluid mechanical shadow means the exoskeleton needs to contain massive computing power, able to read the forces being applied and convert them into signals to control the robot servo motors without any delay. Slow computing would cause mechanical drag for the wearer, who would feel like they were wading through treacle. Not a good idea when you’re trying to save the world.
Pump it up
Humans move by using their muscles in what are called antagonistic pairs. There are always two muscles on either side of the joint that pull the limb in different directions. For example, in your upper arm there are the muscles called the biceps and the triceps. Contracting the biceps muscle bends your elbow up, and contracting your triceps straightens your elbow back. It’s a clever way to control biological movement using just a single type of shortening muscle tissue rather than needing one kind that shortens and another that lengthens.
In an exoskeleton, the robot actuators (the things that do the moving) take the place of the muscles, and we can build these to move however we want, but as the robot’s movements need to shadow the person’s movements inside, the computer needs to understand how humans move. As the human bends their elbow to lift up an object, sensors in the exoskeleton measure the forces applied, and the onboard computer calculates how to move the exoskeleton to minimise the resulting strain on the person’s hand. In strength amplifying exoskeletons the actuators are high pressure hydraulic pistons, meaning that the human operators can lift considerable weight. The hydraulics support the load, the humans movements provide the control.
I knew you were going to do that
It is important that the human user doesn’t need to expend any effort in moving the exoskeleton; people get tired very easily if they have to counteract even a small but continual force. To allow this to happen the computer system must ensure that all the sensors read zero force whenever possible. That way the robot does the work and the human is just moving inside the frame. The sensors can take thousands of readings per second from all over the exoskeleton: arms, legs, back and so on.
This information is used to predict what the user is trying to do. For example, when you are lifting a weight the computer begins by calculating where all the various exoskeleton ‘muscles’ need to be to mirror your movements. Then the robot arm is instructed to grab the weight before the user exerts any significant force, so you get no strain but a lot of gain.
Flight suit?
Exoskeleton systems exist already. Soldiers can march further with heavy packs by having an exoskeleton provide some extra mechanical support that mimics their movements. There are also medical applications that help paralysed patients walk again. Sadly, current exoskeletons still don’t have the ability to let you run faster or do other complex activities like fly.
Flying is another area where the real trick is in the computer programming. Iron Man’s suit is covered in smart ‘control surfaces’ that move under computer control to allow him to manoeuvre at speed. Tony Stark controls his suit through a heads-up display and voice control in his helmet, technology that at least we do have today. Could we have fully functional Iron Man suits in the future? It’s probably just a matter of time, technology and computer science (and visionary multi-millionaire industrialists too).
Peter W McOwanandPaul Curzon, Queen Mary University of London
Imagine swallowing a slug (hint not only a yucky thought but also not a good idea as it could kill you)…now imagine swallowing a slug-bot … also yucky but in the future it might save your life.
When people accidentally swallow solid objects that won’t pass through their digestive system, or are toxic, it can be a big problem. Once an object passes beyond your stomach it becomes hard to get at.
That is where the slug shaped robot comes in (watch the video below). The idea of scientists at the Chinese University of Hong Kong is that a robot like a slug could crawl down your throat to retrieve whatever you had swallowed.
If you think of robots as solid, hard things then that would be the last thing you might want to swallow (aside from an actual slug), and certainly not to catch the previous solid thing you swallowed. You may be right. However, that is where the soft slug-shaped robot comes in.
It is easy to make or buy slime-like “silly” putty. Add iron filings to slime putty and you can make it stretch and sway and even move around with magnets yourself. You can buy such magnetic slime at science museums…it is fun to play with though you definitely shouldn’t swallow it.
The scientists have taken that general idea though and using special materials created a similar highly controllable bot that can be moved around using a magnet-based control system. It is made of a special material that is magnetic and slime-like but coated in silicon dioxide to stop it being poisonous.
They have shown that they can control it to squeeze through narrow gaps and encircle small objects, carrying them away with it…essentially what would be needed to recover objects that have been swallowed.
It needs a lot more work to make sure it is safe to really be swallowed. Also to be a real autonomous robot it would need to have sensors included somehow, and be connected to some sort of intelligent system to automatically control its behaviour. However, with more research that all may become possible.
So in the future if you don’t fancy swallowing a slug-bot, you’d better be far more careful about what else you swallow first. Of course, if it turns out slug like robots can break down, so get stuck themselves, you may then be in a position of needing to swallow a bird-bot to catch the slug-bot. How absurd …
Improvements in technology and decision making are transforming the way we look after our health. Here are some more interesting ideas to keep people alive and well.
The future is in your poo
You’ve heard of telling a person’s future from reading their tea leaves. Scientists believe an effective way of seeing a town’s future may be in the poo. By looking for infection in the waste at sewerage works it’s possible to get fast and accurate local knowledge of where infection rates are high and where low to feed into decision making tools.
Health advice: Stay in the toilet, Stay safe. Help the NHS.
Virtually breaking quarantine
The game, World of Warcraft, a multi-user dungeon game, helped virologists understand how people might behave in pandemics. The game’s developers released a plague that could be passed between avatars. The game’s contaminated area was quarantined. Rather than dying out, the virus escaped – because people broke into the quarantined areas to gawk, then left taking the virus with them.
Health advice: Your avatar should obey quarantine rules too!
The missing bullet holes
To stay healthy in a war, avoid being hit by a bullet. In World War II, many aircraft returned badly damaged. Abraham Wald studied them to decide where better armour was needed. There were more bullet holes in the fuselage than the engines. Where would you add the armour? Abraham added it where there were no bullet holes. He reasoned that the lack of holes in places like engines on returning planes meant that being hit there brought the plane down. Being hit elsewhere did not kill the pilots as those planes made it home!
Health advice: Dodge bullets by making good decisions …
Cybersick of virtual reality
The AI can detect puke-inducing movement and automatically correct the image.
A problem with virtual reality is that wearing a headset can be so immersive that it makes some people actually sick. This happens if you move about when watching a 3D video that was shot from a single place. Artificial intelligence software has come to the rescue, detecting puke-inducing movement and automatically correcting the image.
Health advice: If no bucket, always keep an AI handy.
Shining light on cancers
Cancer treatments like chemotherapy and radiotherapy make patients ill. Some drugs make cancer sensitive to light, allowing tumours to be killed by painlessly shining light on them instead. Sadly, that’s not easy when cancers are inside the body. A new Japanese solution is an LED chip, based on the technology used by contactless payment cards to provide power from a distance. Surgeons place it under the skin and leave it there. They glue it in place using a sticky protein from the feet of mussels. It shines low-intensity green light on the cancer, shrinking it.
Health advice: Stick a chip to your tumour
Smart sometimes means no gadgets
Being smart about health doesn’t have to be high-tech or even involve drugs. Exercise, for example, can be as effective helping with depression as taking medicine. Being out in nature can help too, so sometimes it’s worth leaving the gadgets behind and just going for a walk to enjoy the beauty of nature.
Health advice: Walk weekly in the woods
Paul Curzon, Queen Mary University of London, Spring 2021
Why might a computer scientist need to write fiction? To make sure she creates an app that people actually need.
Writing fiction doesn’t sound like the sort of skill a computer scientist might need. However, it’s part of my job at the moment. Working with expert rheumatologists Amy MacBrayne and Fran Humby, I am helping a design team understand what life with rheumatoid arthritis is like, so they can design software that is actually needed and so will be used and useful.
A big problem with developing software is that programmers tend to design things for themselves. However, programmers are not like the users of their software. They have different backgrounds and needs and they have been trained to think differently. Worse, they know the system they are developing inside out, unlike its users. An important first step in a project is to do background research to understand your users. If designing an app for people with rheumatoid arthritis, you need to know a lot about the lives of such people. To design a successful product, you particularly need to understand their unfulfilled goals. What do they want to be able to do that is currently hard or impossible?
What do you do with the research? Alan Cooper’s idea of ‘Personas’ are a powerful next step – and this is where writing fiction comes in. Based on research, you write descriptions of lots of fictional characters (personas), each representing groups of people with similar goals. They have names, photos and realistic lives. You also write scenarios about their lives that help understand their goals. Next, you merge and narrow these personas down, dropping some, creating new ones, altering others. Your aim is to eventually end up with just one, called a primary persona. The idea is that if you design for the primary persona, you will create something that meets the goals of the groups represented by the other personas it replaced.
The primary persona (let’s call her Samira) is then used throughout the design process as the person being designed for. If wondering whether some new feature or way of doing things is a good idea, the designers would ask themselves, “Would Samira actually want this? Would she be able to use it?” If they can think of her as a real person, it is much easier to make decisions than if thinking of some non-existent abstract “user” who becomes whatever each team member wants them to be. It helps stop ‘feature bloat’ where designers add in every great idea for a new feature they have but end up with a product so complex no one can, or wants to, use it.
As part of the Queen Mary PAMBAYESIAN project we have been talking to rheumatoid arthritis patients and their doctors to understand their needs and goals. I’ve then created a cast of detailed personas to represent the results. These can act as an initial set of personas to help future designers designing apps to support those with the disease.
If you thought creative writing wasn’t important to a computer scientist, think again. A good persona needs to be as powerfully written and as believable as a character in a good novel. So, you should practice writing fiction as well as writing programs.
Some diseases can’t be cured. Doctors and nurses just try to control the disease to stop them ruining people’s lives. Perhaps smartphone apps can pull off the trick of giving patients better care while giving clinicians more time to spend with the patients who most need them? A Venn diagram is at the centre of the Queen Mary team’s prototype.
What is rheumatoid arthritis?
Normally your immune system does a good job of fighting infection and keeping you healthy. But, if you have an autoimmune disease, it can also attack your healthy cells, causing inflammation and damage. Rheumatoid arthritis is like this: a painful condition that mostly affects hands, knees and feet as the person’s immune system attacks their joints, making them swell painfully. It affects around 400,000 people in the UK and is more common in women than men.
People with the disease alternate between periods when it is under control and they have few symptoms, and with days or weeks of painful ‘flares’ where it is very, very bad. During these flares it especially affects a person’s ability to live a normal life. It can be hard to move around comfortably, do exercise – plus it interferes with their ability to work. It can also leave them totally reliant on family and friends just to do everyday things like dress or eat, never mind go out. This can lead to depression and puts a strain on friendships.
Treating the disease
Treatment, which can include tablets, injections, physiotherapy and sometimes surgery, slows the disease, keeping it under control for long periods. Sufferers are also given advice on lifestyle changes. This all reduces the risk of joint damage and helps people live their life more fully.
At appointments, doctors collect information to help them see how the disease is progressing. A Disease Activity Score (DAS) calculator lets them combine measurements for pain, how tender or swollen their patient’s joints are and how many joints are affected. Regular blood tests keep track of the amount of inflammation and how the body is reacting to drugs. This helps them decide if they need to adjust the medication.
If it is caught early, modern medicine reduces the worst effects of the disease, helped by keeping a close eye on the Disease Activity Score as treatments may need to be repeatedly adjusted to control flares. This requires regular hospital visits which uses up scarce healthcare resources and is very time-consuming for patients. It is hampered because hospital appointments may only happen twice a year due to the number of patients. Everyone wants to give more personalised care, but hospitals just can’t afford to provide it.
Supporting doctors
So, what do you do when there just aren’t enough doctors to see everyone as regularly as needed to maintain their patients’ wellbeing? One solution is to use remote monitoring with an app on a patient’s smartphone, so involving patients more directly in their own care. They can use such apps to regularly record their own disease activity measurements, sharing the information with their doctor to save visiting the hospital.
A smart app
This is an improvement, but the measurements still require expert monitoring and can take more of the doctor’s time. However, if smartphones can actually be made to be, well, smart, then they could help give advice between hospital visits and alert the hospital team, when needed, so they can step in. This might involve, for example, loading the app with background knowledge about rheumatoid arthritis, expert knowledge from lots of doctors, and creating an artificial intelligence to use this information effectively for each patient.
Hospital specialists and computer scientists at Queen Mary are developing such a prototype based on Bayesian networks as the artificial intelligence core. Bayesian networks are based on reasoning about the causes of things and how likely different things are to be the cause of something being observed. Building the prototype involves finding out if patients and clinicians find such tools useful and acceptable (some people might find clinic visits reassuring, while some may be keener to avoid taking the time off work, for example).
Smart and patient centred
This still focusses on a clinician’s view of treatment using drugs though. With a smartphone app we can perhaps do better and take the person’s life into account – but how? The first step is to understand patient goals. Patients would need to be willing to share lots of information about themselves so that the software can learn as much as possible about them. Eventually, this might be done using sensors that automatically detect information: how much pain they are in, how stiff their joints are, how much they move around, how long it takes them to get out of a chair, how much sleep they get, how often they meet others, if and when they take their medicine, and so on. Rather than just focussing on medical treatment it can then focus advice ‘holistically’ on the whole person.
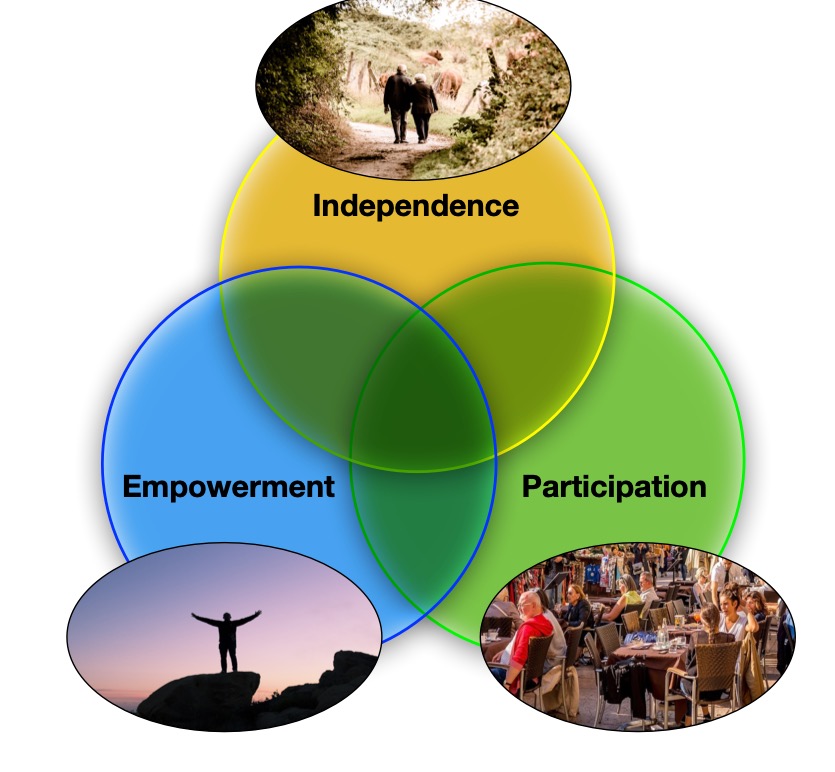
The Queen Mary team’s approach is centred around three different things: helping people with physical independence so they can move around and look after themselves; empowering them to manage their condition and general well-being themselves; and participation in the sense of helping them socialise, keep friendships and maintain family bonds.
The Bayesian network processes the information about patients and computes their predicted levels of independence, empowerment and participation, working out how good or bad things are for them at the moment. This places them in one of seven positions in a Venn diagram of the three dimensions over which areas need most attention. It then gives appropriate advice, aiming to keep all three dimensions in balance, monitoring what happens, but also alerting the hospital when necessary.
So, for example, if the Bayesian network judges independence low, participation high and empowerment low, the patient is in the Venn diagram intersection of low empowerment and low independence. Advice in the following weeks, based on this area of the Venn diagram, would focus on things like coping with pain and stiffness, getting better sleep, as well as how to manage the disease in general.
By personalising advice and focusing on the whole person, it is hoped patients will get more appropriate care as soon as they need it, but doctors’ time will also be freed up to focus on the patients who most need their help.
Jo Brodie, Hamit Soyel and Paul Curzon, Queen Mary University of London, Spring 2021
Fatigue is a problem that people with a variety of long-term diseases can also suffer from.
This isn’t just normal tiredness, but something much, much worse: so bad that it is a struggle to do anything at all, destroying any chance of a normal life. Doctors can often do little to help beyond managing the underlying disease, then hope the fatigue sorts itself out. Sometimes fatigue can stay with the person long, long after. Maha Albarrak, for her PhD, is exploring how computer technology might help people cope. Her first step is to interview those suffering to find out what kind of help they really need. Then she will work closely with volunteers to come up with solutions that solve the problems that matter.
Paul Curzon, Queen Mary University of London, Spring 2021