
If you watch a lot of movies you’ve probably noticed some recurring patterns in the way that popular cinematic stories are structured. Every hero or heroine needs a goal and a villain to thwart that goal. Every goal requires travel along a path that is probably blocked with frustrating obstacles. Heroes may not see themselves as heroes, and will occasionally take the wrong fork in the path, only to return to the one true way before story’s end. We often speak of this path as if it were a race track: a fast-paced story speeds towards its inevitable conclusion, following surprising “twists” and “turns” along the way. The track often turns out to be a circular one, with the heroine finally returning to the beginning, but with a renewed sense of appreciation and understanding. Perhaps we can use this race track idea as a basis for creating stories.
Building a track
If you’ve ever played with a Scalextric set, you will know that the curviest tracks make for the most dramatic stories, by providing more points at which our racing cars can fly off at a tight bend. In Scalextric you build your own race circuits by clicking together segments of prefabricated track, so the more diverse the set of track parts, the more dramatic your circuit can be. We can think of story generation as a similar kind of process. Imagine if you had a large stock of prefabricated plot segments, each made up of three successive bits of story action. A generator could clip these segments together to create a larger story, by connecting the pieces end-to-end. To keep the plot consistent we would only link up sections if they have overlapping actions. So If D-E-F is a segment comprising the actions D, E, and F, we could create the story B-C-D-E-F-G-H by linking the section B-C-D on to the left of D-E-F and F-G-H on its right.
Use a kit
At University College Dublin (UCD) we have created a set of rich public resources that make it easy for you to build your own automated story generator. We call the bundle of resources Scéalextric, from scéal (the Irish word for story) and Scalextric. You can download the Scéalextric resources from our Github but an even better place to start is our blog for people who want to build creative systems of any kind, called Best Of Bot Worlds.
In Artificial Intelligence we often represent complex knowledge structures as ‘graphs’. These graphs consists of lots of labeled lines (called edges) that show how labeled points (called nodes) are connected. That is what our story pieces essentially are. We have several agreed ways for storing these node-relation-node triples, with acronyms hiding long names, like XML (eXtensible Markup Language), RDF (Resource Description Framework) and OWL (Web Ontology Language), but the simplest and most convenient way to create and maintain a large set of story triples is actually just to use a spreadsheet! Yes, the boring spreadsheet is a great way to store and share knowledge, because every cell lies at the intersection of a row and a column. These three parts give us our triples.
Scéalextric is a collection of easy-to-browse spreadsheets that tell a machine how actions connect to form action sequences (like D-E-F above), how actions causally interconnect to each other (via and, then, but), how actions can be “rendered” in natural idiomatic English, and so on.
Adding Character
Automated storytelling is one of the toughest challenges for a researcher or hobbyist starting out in artificial intelligence, because stories require lots of knowledge about causality and characterization. Why would character A do that to character B, and what is character B likely to do next? It helps if the audience can identify with the characters in some way, so that they can use their pre-existing knowledge to understand why the characters do what they do. Imagine writing a story involving Donald Trump and Lex Luthor as characters: how would these characters interact, and what parts of their personalities would they reveal to us through their actions?
Scéalextric therefore contains a large knowledge-base of 800 famous people. These are the cars that will run on our tracks. The entry for each one has triples describing a character’s gender, fictive status, politics, marital status, activities, weapons, teams, domains, genres, taxonomic categories, good points and bad points, and a lot more besides. A key challenge in good storytelling, whether you are a machine or a human, is integrating character and plot so that one informs the other.
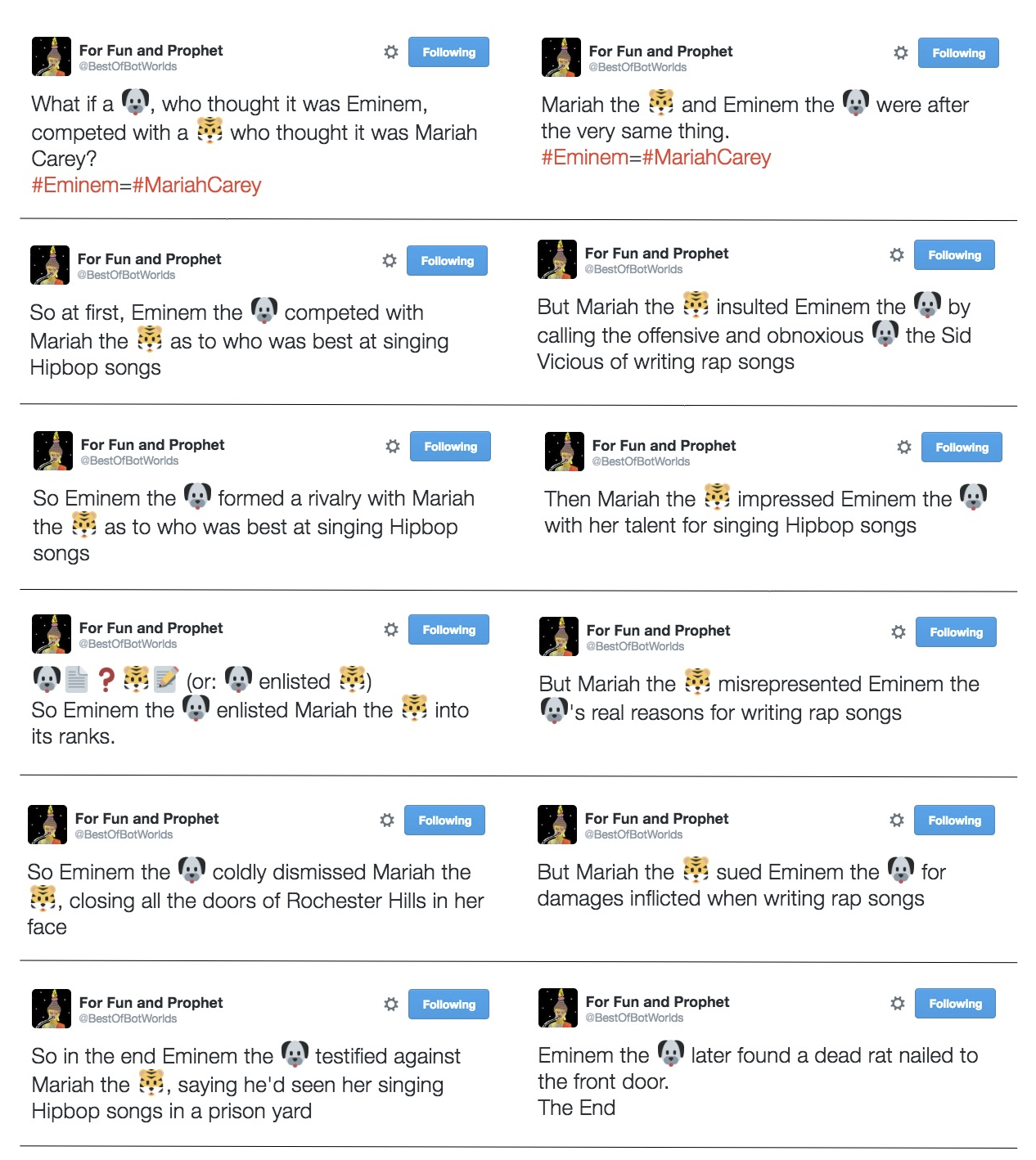
A Twitterbot plot
Let’s look at a story created and tweeted by our Twitterbot @BestOfBotWorlds over a series of 12 tweets. Can you see where the joins are in our Scéalextric track? Can you recognize where character-specific knowledge has been inserted into the rendering of different actions, making the story seem funny and appropriate at the same time? More importantly, can you see how you might connect the track segments differently, choose characters more carefully, or use knowledge about them more appropriately, to make better stories and to build a better story-generator? That’s what Scéalextric is for: to allow you to build your own storytelling system and to explore the path less trodden in the world of computational creativity. It all starts with a click.
Tony Veale, University College Dublin

Further reading
Christopher Strachey came up with the first example of a computer program that could create lines of text (from lists of words). The CS4FN developed a game called ‘Program A Postcard’ (see below) for use at festival events.
Related Magazine …


















.jpg)
