Games are becoming ever more realistic. Now, thanks to the work of Joshua Reiss’s research team and their spinout company, Nemisindo, it’s not just the graphics that are amazing, the sound effects can be too.
There has been a massive focus over the years in improving the graphics in games. We’ve come along way from Pong and its square ball and rectangular paddles. Year after year, decades after decade, new algorithms, new chips and new techniques have been invented that combined with the capabilities of ever faster computers, have meant that we now have games with realistic, real-time graphics immersing us in the action as we play. And yet games are a multimedia experience and realistic sounds matter too if the worlds are to be truly immersive. For decades film crews have included whole teams of Foley editors whose job is to create realistic everyday sounds (check out the credits next time you watch a film!). Whether the sound is of someone walking on a wooden floor in bare feet, walking on a crunchy path,opening thick, plush curtains, or an armoured knight clanging their way down a bare, black cliff, lots of effort goes into getting the sound just right.
Game sound effects are currently often based on choosing sounds from a sound library, but games, unlike films, are increasingly open. Just about anything can happen and make a unique noise while doing so. The chances of the sound library having all the right sounds get slimmer and slimmer.
Suppose a knight character in a game drops a shield. What should it sound like? Well, it depends on whether it is a wooden shield or a metal one. Did it land on its edge or fall horizontally, and was it curved so it rang like a bell? Is the floor mud or did it hit a stone path? Did it bounce or roll? Is the knight in an echoey hall, on a vast plain or clambering down those clanging cliffs…
All of this is virtually impossible to get exactly right if you’re relying on a library of sound samples. Instead of providing pre-recorded sounds as sound libraries do, the software of Josh and team’s company Nemisindo (which is the Zulu word for ‘sound effects’), create new sounds from scratch exactly when they are needed and in real time as a game is played. This approach is called “procedural audio technology”. It allows the action in the game itself to determine the sounds precisely as the sounds are programmed based on setting options for sounds linked to different action scenarios, rather than selecting a specific sound. Aside from the flexibility it gives, this way of doing sound effects gives big advantages in terms of memory too: because sounds are created on the fly, large libraries of sounds no longer need to be stored with the program.
Nemisindo’s new software provides generated procedural sounds for the Unreal game engine allowing anyone building games using the engine to program a variety of action scenarios with realistic sounds tuned to the situation in their game as it happens…
In future, if that Knight steps off the stone path just as she drops her shield the sound generated will take the surface it actually lands on into account…
Procedural sound is the future of sound effects so just as games are now stunning visually, expect them in future to become ever more stunning to listen to too. As they do the whole experience will become ever more immersive… and what works for games works for other virtual environments too. All kinds of virtual worlds just became a lot more realistic. Getting the sound exactly right is no longer a barrier to a perfect experience.
Mike Lynch was one of Britain’s most successful entrepreneurs. An electrical engineer, he built his businesses around machine learning long before it was a buzz phrase. He also drew heavily on a branch of maths called Bayesian statistics which is concerned with understanding how likely, even apparently unlikely, things are to actually happen. This was so central to his success that he named his super yacht, Bayesian, after it. Tragically, he died on the yacht, when Bayesian sank in a freak, extremely unlikely, accident. The gods of the sea are cruel.
Mike started his path to becoming an entrepreneur at school. He was interested in music, and especially the then new but increasingly exciting, digital synthesisers that were being used by pop bands, and were in the middle of revolutionising music. He couldn’t afford one of his own, though, as they cost thousands. He was sure he could design and build one to sell more cheaply. So he set about doing it.
He continued working on his synthesiser project as a hobby at Cambridge University, where he originally studied science, but changed to his by-then passion of electrical engineering. A risk of visiting his room was that you might painfully step on a resistor or capacitor, as they got everywhere. That was not surprising giving his living room was also his workshop. By this point he was also working more specifically on the idea of setting up a company to sell his synthesiser designs. He eventually got his first break in the business world when chatting to someone in a pub who was in the music industry. They were inspired enough to give him the few thousand pounds he needed to finance his first startup company, Lynett Systems.
By now he was doing a PhD in electrical engineering, funded by EPSRC, and went on to become a research fellow building both his research and innovation skills. His focus was on signal processing which was a natural research area given his work on synthesisers. They are essentially just computers that generate sounds. They create digital signals representing sounds and allow you to manipulate them to create new sounds. It is all just signal processing where the signals ultimately represent music.
However, Mike’s research and ideas were more general than just being applicable to audio. Ultimately, Mike moved away from music, and focussed on using his signal processing skills, and ideas around pattern matching to process images. Images are signals too (resulting from light rather than sound). Making a machine understand what is actually in a picture (really just lots of patches of coloured light) is a signal processing problem. To work out what an image shows, you need to turn those coloured blobs into lines, then into shapes, then into objects that you can identify. Our brains do this seamlessly so it seems easy to us, but actually it is a very hard problem, one that evolution has just found good solutions to. This is what happens whether the image is that captured by the camera of a robot “eye” trying to understand the world or a machine trying to work out what a medical scan shows.
This is where the need for maths comes in to work out probabilities, how likely different things are. Part of the task of recognising lines, shapes and objects is working out how likely one possibility is over another. How likely is it that that band of light is a line, how likely is it that that line is part of this shape rather than that, and so on. Bayesian statistics gives a way to compute probabilities based on the information you already know (or suspect). When the likelihood of events is seen through this lens, things that seem highly unlikely, can turn out to be highly probably (or vice versa), so it can give much more accurate predictions than traditional statistics. Mike’s PhD used this way of calculating probabilities even though some statisticians disdained it. Because of that it was shunned by some in the machine learning community too, but Mike embraced it and made it central to all his work, which gave his programs an edge.
While Lynett Systems didn’t itself make him a billionaire, the experience from setting up that first company became a launch pad for other innovations based on similar technology and ideas. It gave him the initial experience and skills, but also meant he had started to build the networks with potential investors. He did what great entrepreneurs do and didn’t rest on his laurels with just one idea and one company, but started to work on new ideas, and new companies arising from his PhD research.
He realised one important market for image pattern recognition, that was ripe for dominating, was fingerprint recognition. He therefore set about writing software that could match fingerprints far faster and more accurately than anyone else. His new company, Cambridge Neurodynamics, filled a gap, with his software being used by Police Forces nationwide. That then led to other spin-offs using similar technology
He was turning the computational thinking skills of abstraction and generalisation into a way to make money. By creating core general technology that solved the very general problems of signal processing and pattern matching, he could then relatively easily adapt and reuse it to apply to apparently different novel problems, and so markets, with one product leading to the next. By applying his image recognition solution to characters, for example, he created software (and a new company) that searched documents based on character recognition. That led on to a company searching databases, and finally to the company that made him famous, Autonomy.
One of his great loves was his dog, Toby, a friendly enthusiastic beast. Mike’s take on the idea of a search engine was fronted by Toby – in an early version, with his sights set on the nascent search engine market, his search engine user interface involved a lovable, cartoon dog who enthusiastically fetched the information you needed. However, in business finding your market and getting the right business model is everything. Rather than competing with the big US search engine companies that were emerging, he switched to focussing on in-house business applications. He realised businesses were becoming overwhelmed with the amount of information they held on their servers, whether in documents or emails, phone calls or videos. Filing cabinets were becoming history and being replaced by an anarchic mess of files holding different media, individually organised, if at all, and containing “unstructured data”. This kind of data contrasts with the then dominant idea that important data should be organised and stored in a database to make processing it easier. Mike realised that there was lots of data held by companies that mattered to them, but that just was not structured like that and never would be. There was a niche market there to provide a novel solution to a newly emerging business problem. Focussing on that, his search company, Autonomy, took off, gaining corporate giants as clients including the BBC. As a hands-on CEO, with both the technical skills to write the code himself and the business skills to turn it into products businesses needed, he ensured the company quickly grew. It was ultimately sold for $11 billion. (The sale led to an accusation of fraud in hte US, but, innocent, he was acquitted of all the charges).
Investing
From firsthand experience he knew that to turn an idea into reality you needed angel investors: people willing to take a chance on your ideas. With the money he made, he therefore started investing himself, pouring the money he was making from his companies into other people’s ideas. To be a successful investor you need to invest in companies likely to succeed while avoiding ones that will fail. This is also about understanding the likelihood of different things, obviously something he was good at. When he ultimately sold Autonomy, he used the money to create his own investment company, Invoke Capital. Through it he invested in a variety of tech startups across a wide range of areas, from cyber security, crime and law applications to medical and biomedical technologies, using his own technical skills and deep scientific knowledge to help make the right decisions. As a result, he contributed to the thriving Silicon Fen community of UK startup entrepreneurs, who were and continue to do exciting things in and around Cambridge, turning research and innovation into successful, innovative companies. He did this not only through his own ideas but by supporting the ideas of others.
Mike was successful because he combined business skills with a wide variety of technical skills including maths, electronic engineering and computer science, even bioengineering. He didn’t use his success to just build up a fortune but reinvested it in new ideas, new companies and new people. He has left a wonderful legacy as a result, all the more so if others follow his lead and invest their success in the success of others too.
Just because you start a start-up doesn’t mean you have to be the boss (the CEO) running the company… Hamit Soyel didn’t and his research-based company, DragonFlyAI is flourishing.
Hamit’s computer science research (with Peter McOwan) at Queen Mary concerns understanding human (and animal) vision systems. Building on the research of neuroscientists they created computational models of vision systems. These are just programs that work in the way we believe our brains process what we see. If our understanding is correct then the models should see as we see. For example, one aspect of this is how our attention is drawn to some things and not others. If the model is accurate, it should be able to predict things we will definitely notice, and predict things we probably won’t. It turned out their models were really good at this.
They realised that their models had applications in marketing and advertising (an advert that no one notices is a waste of money). They therefore created a startup company based on their research. Peter sadly died not long after the company was founded leaving Hamit to make it a success. He had a choice to make though. Often people who start a startup company set themselves up as the CEO: it is their company so they want control. To do this you need good business skills though and also to be willing to devote the time to make the business a success. You got to this point though because of your technical and creative skills,
When you start a company you want to make a difference, but to actually do that you need a strong team and that team doesn’t have to be “behind” you, they can be “with” you – after all the best teams are made up of specialists who work to their strengths as well as supporting and working well with each other. Perhaps your strengths lie elsewhere, rather than in running a business,
With support from Queen Mary Innovations who helped him set up DragonflyAI and have supported it through its early years, Hamit decided his strengths were in the creative and technical side of the business, so he became the Chief Scientist and Inventor rather than the CEO. That role was handed to an expert as were the other senior leadership roles such as Marketing and Sales, Operations and Customer Success. That meant Hamit could focus on what he did best in further developing the models, as well as in innovating new ideas. This approach also gives confidence to investors that the leadership team do know what they are doing and that if they like the ideas then the company will be a success.
As a result, Hamit’s business is now a big success having helped a whole series of global companies improve their marketing, including Mars and Coca-Cola. DragonflyAI also recently raised $6m in funding from investors to further develop the business.
As Hamit points out:
By delegating operations to a professional leadership team, you can concentrate on areas you truly enjoy that fuel your passion and creativity, ultimately enhancing your fulfilment and contribution to your company and driving collective success.”
To be the CEO or not be the CEO depends on your skills and ambition, but you must also think about what is best for the company, as Hamit has pointed out. It is important to realise though that you do not have to be the CEO just because you founded the company.
Paul Curzon, Queen Mary University of London,
based on an interview between Hamit Soyel and Queen Mary Innovations
Becoming a successful entrepreneur often starts with seeing a need: a problem someone has that needs to be fixed. For David Ronan, the need was for anyone to mix and master music but the problem was that of how hard it is to do this. Now his company RoEx is fixing that problem by combining signal processing ans artificial intelligence tools applied to music. It is based on his research originally as a PhD student
Musicians want to make music, though by “make music” they likely mean playing or composing music. The task of fiddling with buttons, sliders and dials on a mixing desk to balance the different tracks of music may not be a musician’s idea of what making music is really about, even though it is “making music” to a sound engineer or producer. However, mixing is now an important part of the modern process of creating professional standard music.
This is in part a result of the multitrack record revolution of the 1960s. Multitrack involves recording different parts of the music as different tracks, then combining them later, adding effects, combining them some more … George Martin with the Beatles pioneered its use for mainstream pop music in the 1960s and the Beach Boys created their unique “Pet Sounds” through this kind of multitrack recording too. Now, it is totally standard. Originally, though, recording music involved running a recording machine while a band, orchestra and/or singers did their thing together. If it wasn’t good enough they would do it all again from the beginning (and again, and again…). This is similar to the way that actors will act the same scene over and over dozens of times until the director is happy. Once happy with the take (or recording) that was basically it and they moved on to the next song to record.
With the advent of multitracking, each musician could instead play or sing their part on their own. They didn’t have to record at the same time or even be in the same place as the separate parts could be mixed together into a single whole later. Then it became the job of engineers and the producer to put it all together into a single whole. Part of this is to adjust the levels of each track so they are balanced. You want to hear the vocals, for example, and not have them drowned out by the drums. At this point the engineer can also fix mistakes, cutting in a rerecording of one small part to replace something that wasn’t played quite right. Different special effects can also be applied to different tracks (playing one track at a different speed or even backwards, with reverb or auto-tuned, for example). You can also take one singer and allow them to sing with multiple versions of themselves so that they are their own backing group, and are singing layered harmonies with themselves. One person can even play all the separate instruments as, for example, Prince often did on his recordings. The engineers and producer also put it all together and create the final sound, making the final master recording. Some musicians, like Madonna, Ariana Grande and Taylor Swift do take part in the production and engineering parts of making their records or even take over completely, so they have total control of their sound. It takes experience though and why shouldn’t everyone have that amount of creative control?
Doing all the mixing, correction and overdubbing can be laborious and takes a lot of skill, though. It can be very creative in itself too, which is why producers are often as famous as the artists they produce (think Quincy Jones or Nile Rogers, for example). However, not everyone wanting to make their own music is interested in spending their time doing laborious mixing, but if you don’t yet have the skill yourself and cant afford to pay a producer what do you do?
That was the need that David spotted. He wanted to do for music what instagram filters did for images, and make it easy for anyone to make and publish their own professional standard music. Based in part on his PhD research he developed tools that could do the mixing, leaving a musician to focus on experimenting with the sound itself.
David had spent several years leading the research team of an earlier startup he helped found called AI Music. It worked on adaptive music: music that changes based on what is happening around it, whether in the world or in a video game being played. It was later bought by Apple. This was the highlight of his career to that point and it helped cement his desire to continue to be an innovator and entrepreneur.
With the help of Queen Mary, where he did his PhD, he therefore decided to set up his new company RoEx. It provides an AI driven mixing and mastering service. You choose basic mixing options as well as have the ability to experiment with different results, so still have creative control. However, you no longer need expensive equipment, nor need to build the skills to use it. The process becomes far faster too. Mixing your music becomes much more about experimenting with the sound: the machine having taken over the laborious parts, working out the optimum way to mix different tracks and produce a professional quality master recording at the end.
David didn’t just see a need and have an idea of how to solve it, he turned it into something that people want to use by not only developing the technology, but also making sure he really understood the need. He worked with musicians and producers through a long research and development process to ensure his product really works for any musician.
Queens is a fairly simple kind of logic puzzle found for example on LinkedIn as a way to draw you back to the site. Doing daily logic puzzles is good both for mental health and to build logical thinking skills. As with programming, solving logic puzzles is mostly about pattern matching (also a useful skill to practice daily) rather than logic per se. The logic mainly comes in working out the patterns.
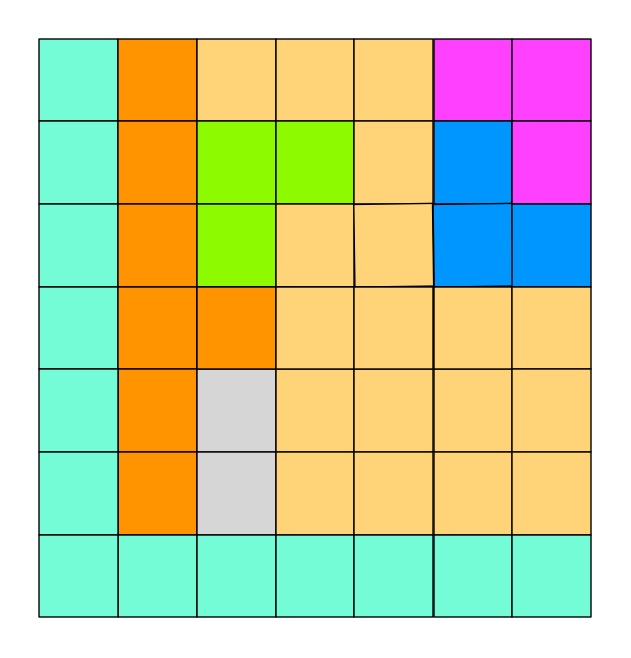
Let’s explore this with Queens. The puzzle has simple rules. The board is divided into coloured territories and you must place a Queen in each territory. However, no two Queens can be in the same row or column. Also no two Queens can be adjacent, horizontally, vertically or diagonally.
If we were just to use pure logic on these puzzles we would perhaps return to the rules themselves constantly to try and deduce where Queens go. That is perhaps how novices try to solve puzzles (and possibly get frustrated and give up). Instead, those who are good at puzzles create higher level rules that are derived from the basic rules. Then they apply (ie pattern match against) the new rules whenever the situation applies. As an aside this is exactly how I worked when using machine-assisted proof to prove that programs and hardware correctly met their specification, doing research into better ways to ensure the critical devices we create are correct.
Let’s look at an example from Queens. Here is a puzzle to work on. Can you place the 8 Queens?
mage by Paul Curzon
mage by Paul Curzon
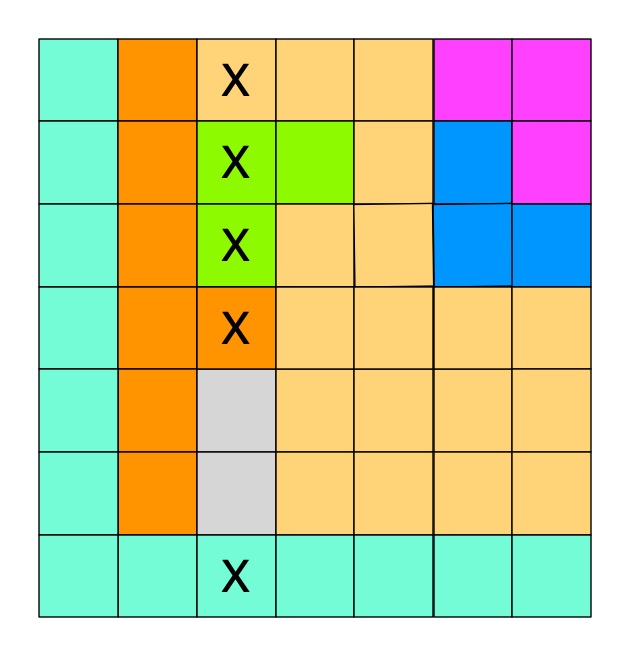
Where to start? Well notice the grey territory near the bottom. It is a territory that lives totally in one column. If we go to the rules of Queens we know that there must be a Queen in this territory. That means that Queen must be in that column. We also know that only one Queen can be in a column. That means none of the other territories in that column can possibly hold a Queen there. We can cross them all out as shown.
In effect we have created a new derived inference rule.
IF a territory only has squares available in one column
THEN cross out all squares of other territories in that column
By similar logic we can create a similar rule for rows.
Now we can just pattern match against the situation described in that rule. If ever you see a territory contained completely in a row or column, you can cross out everything else in that row/column.
In our case in doing that it creates new situations that match the rule. You may also be able to work out other rules. One obvious new rule is the following:
IF a territory only has one free space left and no Queens
THEN put a Queen in that free space
mage by Paul Curzon
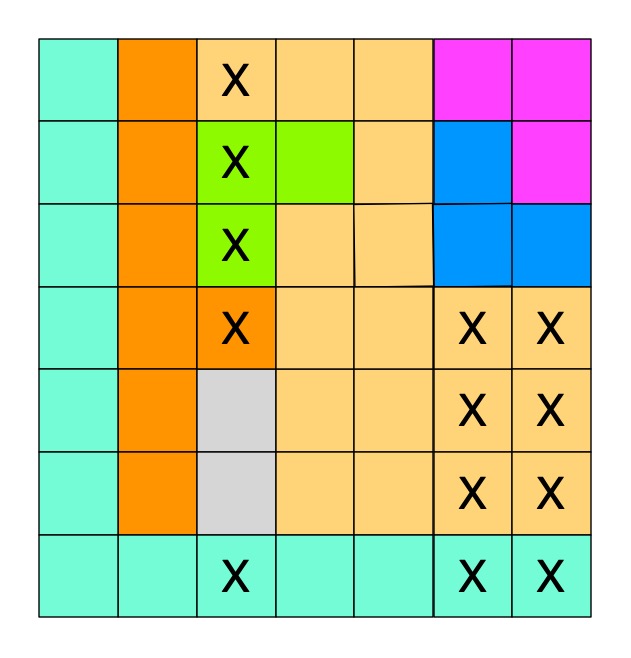
We can derive more complicated rules too. For example, we can generalise our first rule to two columns. Can you find a pair of territories that reside in the same two columns only? There is such a pair in the top right corner of our puzzle. If there is such a situation then as both must have a Queen, between them they must be the territories that provide the Queens for both those two columns. That means we can cross out all the squares from other territories in those two columns. We get the rule:
IF two territories only have squares available in two columns
THEN cross out all squares of other territories in both columns
Becoming good at Queens puzzles is all about creating more of these rules that quickly allow you to make progress in all situations. As you apply rules, new rules become applicable until the puzzle is solved.
Can you both apply these rules and if need be derive some more to pattern match your way to solving this puzzle?
It turns out that programming is a lot like this too. For a novice, writing code is a battle with the details of the semantics (the underlying logical meaning) of the language finding a construct that does what is needed. The more expert you become the more you see patterns where you have a rule you can apply to provide the code solution: IF I need to do this repeatedly counting from 1 to some number THEN I use a for loop like this… IF I have to process a 2 dimensional matrix of possibilities THEN I need a pair of nested for loops that traverse it by rows and columns… IF I need to do input validation THEN I need this particular structure involving a while loop… and so on.
Perhaps more surprisingly, research into expert behaviour suggests that is what all expert behaviour boils down to. Expert intuition is all about subconscious pattern matching for situations seen before turned into subconscious rules whether expert fire fighters or expert chess players. Now machine learning AIs are becoming experts at things we are good at. Not suprisingly, what machine learning algorithms are good at is spotting patterns to drive their behaviour.
Mid-September, as many young people are heading back to school after their summer holiday, is Asthma Week where NHS England suggests that teachers, employers and government workers #AskAboutAsthma. The goal is to raise awareness of the experiences of those with asthma, and to suggest techniques to put in place to help children and young people with asthma live their best lives.
One of the key bits of kit in the arsenal of people with asthma is an inhaler. When used, an inhaler can administer medication directly into the lungs and airways as the user breathes in. In the case of those with asthma, an inhaler can help to reduce inflammation in the airways which might prevent air from entering the lungs, especially during an asthma attack.
It’s only recently, however, that inhalers are getting the technology treatment. Smart inhalers can help to remind those with asthma to take their medication as prescribed (a common challenge for those with asthma) as well as tracking their use which can be shared with doctors, carers, or parents. Some smart inhalers can also identify if the correct inhaler technique is being used. Researchers have been able to achieve this by putting the audio of people using an inhaler through a neural network (a form of artificial intelligence), which can then classify between a good and bad technique.
As with any medical technology, these smart inhalers need to be tested with people with asthma to check that they are safe and healthy, and importantly to check that they are better than the existing solutions. One such study started in Leicester in July 2024, where smart inhalers (in this case, ones that clip onto existing inhalers) are being given to around 300 children in the city. The researchers will wait to see if these children have better outcomes than those who are using regular inhalers.
This sort of technology is a great example of what computer scientists call the “Internet of Things” (IoT). This refers to small computers which might be embedded within other devices which can interact over the internet… think smart lights in your home that connect to a home assistant, or fridges that can order food when you run out.
A lot of medical devices are being integrated into the internet like this… a smart watch can track the wearer’s heart rate continuously and store it in a database for later, for example. Will this help us to live happier, healthier lives though? Or could we end up finding concerning patterns where there are none?
What could a blind or partially-sighted person get from a visit to an art gallery? Quite a lot if the art gallery puts their mind to it. Even more if they make use of technology. So much so, we may all want the enhanced experience.
The best art galleries provide special tours for blind and partially-sighted people. One kind involves a guide or curator explaining paintings and other works of art in depth. It is not exactly like a normal guided tour that might focus on the history or importance of a painting. The best will give both an overview of the history and importance whilst also giving a detailed description of the whole picture as well as the detail, emphasising how each part was painted. They might, for example, describe the brush strokes and technique as well as what is depicted. They help the viewer create a really detailed mental model of the painting.
One visually-impaired guide who now gives such tours at galleries such as Tate Britain, Lisa Squirrel, has argued that these tours give a much deeper and richer understanding of the art than a normal tour and certainly more than someone just looking at the pictures and reading the text as they wander around. Lisa studied Art History at university and before visiting a gallery herself reads lots and lots about the works and artists she will visit. She found that guided tours by sighted experts using guided hand movements in front of a painting helped her build really good internal models of the works in her mind. Combined with her extensive knowledge from reading, she wasn’t building just a picture of the image depicted but of the way it was painted too. She gained a deep understanding of the works she explored including what was special about them.
The other kind of tour art galleries provide is a touching tour. It involves blind and partially-sighted visitors being allowed to touch selected works of art as part of a guided tour where a curator also explains the art. Blind art lover, Georgina Kleege, has suggested that touch tours give a much richer experience than a normal tour, and should also be put on for all for this reason. It is again about more than just feeling the shape and so “working out its form that”seeing” what a sighted person would take in at a glance. It is about gaining a whole different sensory experience of the work: its texture, for example, not a lesser version just of what it looks like.
How might technology help? Well, the company, NeuroDigital Technologies, has developed a haptic glove system for the purpose. Haptic gloves are gloves that contain vibration pads that stimulate the skin of the person in different, very fine ways so as to fool the wearer’s brain into thinking it is touching things of different shapes and textures. Their system has over a thousand different vibration patterns to simulate different feelings of touching surfaces. They also contain sensors that determine the precise position of the gloves in space as the person moves their hands around.
The team behind the idea scanned several works of art using very accurate laser scanners that build up a 3D picture of the thing being scanned. From this they created a 3D model of the work. This then allowed a person wearing to feel as though they were touching the actual sculpture feeling all the detail. More than that the team could augment the experience to give enhanced feelings in places in shadow, for example, or to emphasise different parts of the work.
A similar system could be applied to historical artifacts too: allowing people to “feel” not just see the Rosetta Stone, for example. Perhaps it could also be applied to paintings to allow a person to feel the brush strokes in a way that could just not otherwise be done. This would give an enhanced version of the experience Lisa felt was so useful of having her hand guided in front of a painting and the brush strokes and areas being described. Different colours might also be coded with different vibration patterns in this way allowing a series of different enhanced touch tours of a painting, first exploring its colours, then its brush strokes, and so on.
What about talking tours? Can technology help there? AIs can already describe pictures, but early versions at least were trained on the descriptions people have given to images on the Internet: “a black cat sitting on top of the TV looking cute”, The Mona Lisa: a young woman staring at you”. That in itself wouldn’t cut it. Neither would training the AI on the normal brief descriptions on the gallery walls next to works of art. However, art books and websites are full of detail and more recent AIs can give very detailed descriptions of art works if asked. These descriptions include what the picture looks like overall, the components, colours, brushstrokes and composition, symbolism, historical context and more (at least for famous paintings). With specific training from curators and art historians the AIs will only get better. What is still missing for a blind person though from the kind of experience Lisa has when experiencing painting with a guide, is the link to the actual picture in space – having the guide move her hand in front of the painting as the parts are described. However, all that is needed to fill that gap is to combine a chat-based AI with a haptic glove system (and provide a way to link descriptions to spatial locations on the image). Then, the descriptions can be linked to positions of a hand moving in space in front of a virtual version of the picture. Combine that with the kind of system already invented to help blind people navigate, where vibrations on a walking stick indicate directions and times to turn, and the gloves can then not only give haptic sensations of the picture in front of the picture or sculpture, but also guide the person’s movement over it.
Whether you have such an experience in a gallery, in front of the work of art, or in your own front room, blind and partially sighted people could soon be getting much better experiences of art than sighted people. At which point, as Georgina Kleege, suggested for normal touch tours, everyone else will likely want the full “blind” experience too.
Before mobile games, game consoles and PC based games, video games first took off in arcades. Arcade games were very big earning 39 billion dollars at their peak in the 1980s. Games were loaded into bespoke coin-operated arcade machines. For a game to do well someone had to buy the machines, whether actual gaming arcades or bars, cafes, colleges, shopping malls, … Then someone had to play them. Originally boys played arcade games the most and so games were targeted at them. Most games had a focus on shooting things: games like asteroids and space invaders or had some link to sports based on the original arcade game Pong. Girls were largely ignored by the designers… But then came Pac-Man.
Pac-Man, created by a team led by Toru Iwatani, is a maze game where the player controls the Pac-Man character as it moves around a maze, eating dots while being chased by the ghosts: Blinky, Pinky, Inky, and Clyde. Special power pellets around the maze, when eaten, allow Pac-Man to chase the ghosts for a while instead of being chased.
Pac-Man ultimately made around $19 million dollars in today’s money making it the biggest money making video arcade game of all time. How did it do it? It was the first game that was played by more females than males. It showed that girls would enjoy playing games if only the right kind of games were developed. Suddenly, and rather ironically given its name, there was a reason for the manufacturers to take notice of girls, not just boys.
It revolutionised games in many ways, showing the potential of different kinds of features to give it this much broader appeal. Most obviously Pac-Man did this by turning the tide away from shoot-em up space games and sports games to action games where characters were the star of the game, and that was one of its inventor Toru Iwatani’s key aims. To play you control Pac-Man rather than just a gun, blaster, tennis racket or golf club. It paved the way for Donkey Kong, Super Mario, and the rest (so if you love Mario and all his friends, then thank Pac-Man). Ultimately, it forged the path for the whole idea of avatars in games too.
It was the first game to use power ups where, by collecting certain objects, the character gains extra powers for a short time. The ghosts were also characters controlled by simple AI – they didn’t just behave randomly or follow some fixed algorithm controlling their path, but reacted to what the player does, and each had their own personality in the way they behaved.
Because of its success, maze and character-based adventure games became popular among manufacturers, but more importantly designers became more adventurous and creative about what a video game could be. It was also the first big step towards the long road to women being fully accepted to work in the games industry. Not bad for a character based on a combination of a pizza and the Japanese symbol for “mouth”.
What makes a good environment for child AI learning development? Possibly the same as for human child learning development: Minecraft.
Lego is one of the best games to play for impactful learning development for children. The word Lego is based on the words Play and Well in Danish. In the virtual world, Minecraft has of course taken up the mantle. A large part of why they are wonderful games is because they are open-ended and flexible. There are infinite possibilities over what you can build and do. They therefore help encourage not just focussing on something limited to learn as many other games do, but support open-ended creativity and so educational development. Given how positive it can be for children, it shouldn’t be surprising that Minecraft is now being used to help AIs develop too.
Games have long been used to train and test Artificial Intelligence programs. Early programs were developed to play and ultimately beat humans at specific games like Checkers, Chess and then later Go. That mastered they started to learn to play individual arcade games as a way to extend their abilities. A key part of our intelligence is flexibility though, we can learn new games. Aiming to copy this, the AIs were trained to follow suit and so became more flexible, and showed they could learn to play multiple arcade games well.
This is still missing a vital part of our flexibility though. The thing about all these games is that the whole game experience is designed to be part of the game and so the task the player has to complete. Everything is there for a reason. It is all an integral part of the game. There are no pieces at all in a chess game that are just there to look nice and will never, ever play a part in winning or losing. Likewise all the rules matter. When problem solving in real life, though, most of the world, whether objects, the way things behave or whatever, is not there explicitly to help you solve the problem. It is not even there just to be a designed distractor. The real world also doesn’t have just a few distractors, it has lots and lots. Looking round my living room, for example, there are thousands of objects, but only one will help me turn on the tv.
AIs that are trained on games may, therefore, just become good at working in such unreal environments. They may need to be told what matters and what to ignore to solve problems. Real problems are much more messy, so put them in the real world, or even a more realistic virtual world, to problem solve and they may turn out to be not very clever at all. Tests of their skills that are based on such tasks may not really test them at all.
Researchers at the University of Witwatersrand in South Africa decided to tackle this issue, but using yet another game: Minecraft. Because Minecraft is an open-ended virtual world, tackling challenges created in it will involve working in a world that is much more than just about the problem itself. The Witwatersrand team’s resulting MinePlanner system is a collection of 45 challenges, some easy, some harder. They include gathering tasks (like finding and gathering wood) and building tasks (like building a log cabin), as well as tasks that include combinations of these things. Each comes in three versions. In the easy version nothing is irrelevant. The medium version contains a variety of extraneous things that are not at all useful to the task. The hard version is in a full Minecraft world where there are thousands of objects that might be used.
To tackle these challenges an AI (or human) needs to solve not just the complex problem set, but also work out for themselves what in the Minecraft world is relevant to the task they are trying to perform and what isn’t. What matters and what doesn’t?
The team hope that by setting such tests they will help encourage researchers to develop more flexible intelligences, taking us closer to having real artificial intelligence. The problems are proposed as a benchmark for others to test their AIs against. The Witwatersrand team have already put existing state-of-the-art AI planning systems to the test. They weren’t actually that great at solving the problems and even the best could not complete the harder tasks.
So it is back to school for the AIs but hopefully now they will get a much better, flexible and fun education playing games like Minecraft. Let’s just hope the robots get to play with Lego too, so they don’t get left behind educationally.
One of the ways that computers could be more like humans – and maybe pass the Turing test – is by responding to emotion. But how could a computer learn to read human emotions out of words? Matthew Purver of Queen Mary University of London tells us how.
Have you ever thought about why you add emoticons to your text messages – symbols like 🙂 and :-@? Why do we do this with some messages but not with others? And why do we use different words, symbols and abbreviations in texts, Twitter messages, Facebook status updates and formal writing?
In face-to-face conversation, we get a lot of information from the way someone sounds, their facial expressions, and their gestures. In particular, this is the way we convey much of our emotional information – how happy or annoyed we’re feeling about what we’re saying. But when we’re sending a written message, these audio-visual cues are lost – so we have to think of other ways to convey the same information. The ways we choose to do this depend on the space we have available, and on what we think other people will understand. If we’re writing a book or an article, with lots of space and time available, we can use extra words to fully describe our point of view. But if we’re writing an SMS message when we’re short of time and the phone keypad takes time to use, or if we’re writing on Twitter and only have 140 characters of space, then we need to think of other conventions. Humans are very good at this – we can invent and understand new symbols, words or abbreviations quite easily. If you hadn’t seen the 😀 symbol before, you can probably guess what it means – especially if you know something about the person texting you, and what you’re talking about.
But computers are terrible at this. They’re generally bad at guessing new things, and they’re bad at understanding the way we naturally express ourselves. So if computers need to understand what people are writing to each other in short messages like on Twitter or Facebook, we have a problem. But this is something researchers would really like to do: for example, researchers in France, Germany and Ireland have all found that Twitter opinions can help predict election results, sometimes better than standard exit polls – and if we could accurately understand whether people are feeling happy or angry about a candidate when they tweet about them, we’d have a powerful tool for understanding popular opinion. Similarly we could automatically find out whether people liked a new product when it was launched; and some research even suggests you could even predict the stock market. But how do we teach computers to understand emotional content, and learn to adapt to the new ways we express it?
One answer might be in a class of techniques called semi-supervised learning. By taking some example messages in which the authors have made the emotional content very clear (using emoticons, or specific conventions like Twitter’s #fail or abbreviations like LOL), we can give ourselves a foundation to build on. A computer can learn the words and phrases that seem to be associated with these clear emotions, so it understands this limited set of messages. Then, by allowing it to find new data with the same words and phrases, it can learn new examples for itself. Eventually, it can learn new symbols or phrases if it sees them together with emotional patterns it already knows enough times to be confident, and then we’re on our way towards an emotionally aware computer. However, we’re still a fair way off getting it right all the time, every time.