Have you ever followed a recipe perfectly, only to find the cake tastes… well, a bit weird? You followed every rule, measured every ingredient, and checked every step. The recipe said you did it right. But your taste buds, and your grandma’s disappointed sigh, told you something was definitely wrong. In the world of computer science, we have this problem all the time. We call it the difference between verification and validation.
Verification is like checking the recipe. Did you follow the rules exactly as written? A computer program called a “verifier” can look at the code a programmer wrote and check it against the “recipe” (the formal specification). If the code matches the recipe, it gets a big green checkmark. It’s officially “correct.”
But validation is like the taste test. Does the final cake actually taste good? Does it make people happy? This is about asking: did we make the right thing?
The Case of the Annoying Vending Machine
Imagine a new high-tech vending machine. Its specification (its recipe) says: “If a user inserts money and the selected item is out of stock, return the money.”
A programmer builds the machine. A verifier checks it. You put in a pound, press “B2” for salt and vinegar crisps, and it’s out of stock. The machine correctly spits your pound coin back out onto the floor.
Is the machine correct? According to the recipe, yes! Verification passed. Is it the right machine? No! It’s incredibly annoying!
Your expectation as a human was probably completely different. You expected it to say, “Sorry, B2 is out of stock. Please choose something else.” You expected it to hold onto your money and let you make another choice. Cheese and Onion Crisps are just as good. The machine followed the rules, but it completely misunderstood what you, the user, actually wanted. It was correct, but wrong.
This is the frustrating gap where most “bad” software lives. It follows its own strange rules perfectly but seems to have no common sense about what people actually expect.
Teaching the Genie to Read Minds (Almost!)
So how do we fix this? Our research introduces an idea called Semantic Expectation Logic (SEL). It sounds complicated, but the core idea is simple: what if we could teach the computer to understand not just its own recipe, but also the collection of fuzzy, unwritten expectations that people have in their heads?
Think of it like upgrading from a rule-following genie to a mind-reading one.
A rule-following genie gives you exactly what you wish for. If you wish to “be on a flight”, it might put you on the wing of a 747. Technically correct, but not what you expected!
SEL is our attempt to build a “mind-reading” genie for software. We do it in three steps:
Write Down the Rules of the World: We tell the computer about fundamental truths. For the vending machine, a rule might be “Money can only be returned after a transaction is finished or explicitly cancelled by the user.”
Ask People What They Expect: Instead of guessing, we show people what the machine does in different situations. “The machine just spat your coin on the floor. Is that what you expected?” We collect all these “yes” and “no” answers, along with why. We call this “mining expectations”.
Check for Gaps: Our SEL tool then looks at what the machine actually does and compares it to both the “Rules of the World” and the “Mined Expectations”.
It might find:
A Bug: The machine sets itself on fire. (It violates a Rule of the World: “Vending machines should not set themselves on fire.”)
A Validation Failure (The “Aha!” Moment): The machine follows its own rules perfectly but violates a strong expectation. Our tool would flag this: “Warning! 98% of people expected the machine to ask for another choice, but it just returned the money. This is a Surprise!”
We even created a “Surprise Factor” metric that gives a score from 0% to 100% for how surprising a piece of software is. A low score means the software behaves as people expect. A high score means you’ve built a technically “correct” but incredibly annoying vending machine.
By making expectations a central part of the testing process, we can start building software that isn’t just correct according to its own bizarre logic, but is also correct in a way that actually makes sense to the people using it. We can build the cake that not only follows the recipe but also tastes great.
For Valentine’s day we created this card with a pseudocode love poem. But what does it mean? Is it a statement of love or not? Now that Valentines Day is gone and logic and rational thinking are starting to reassert themselves, here is a logical argument of what it means: an informal proof of love.
We are using our own brand of poetic pseudocode here, and what matters is the formal semantics of the language (ie mathematical meaning).
What we will do is simplify the code to code that is mathematically equivalent but far simpler, explaining the semantics as we do. We will by reasoning in a similar way to doing algebra, just replacing equals with equals.
First let’s write the poem out in more program looking notation, making clearer what are statements (actions) and expressions (things that evaluate to a value. In the English reading version we are using the verb TO BE in both ways which confuses things a little.
Let’s make clear the difference between variables (that hold values and values). The colours are all values (data that can be stored) – so we will write them in capitals: RED, BLUE, VIOLET. The flowers are variables (places to store values) so we will leave them as lowercase: violets, roses. Then the title becomes an assignment (written more formally as :=). It sets the value of variable violets to value VIOLET. (We are pedantic and believe the colour of violet flowers is violet not blue!)
What comes after the keyword IF is an expression – it evaluates to a boolean (TRUE value or FALSE value) so is referred to as a boolean expression. You can think of boolean expressions as tests – true or false questions. We will use == to indicate a true/false question about whether two things are the same value.
The other two lines are statements – think of them as print statements that print a message as the action they do.
The algorithm of the poem then is:
violets := VIOLET; IF ((roses == RED) AND (violets == BLUE)) THEN PRINT "Life is Sweet" ELSE PRINT "I love you"
Now let us simplify the algorithm to an equivalent version a step at a time. In the assignment of the first line, the variable violets is set to value VIOLET and then not changed, so we can substitute the value (a colour in uppercase) VIOLET for variable violets (in lowercase) where it appears, and remove the assignment. This gives a simpler version of the algorithm that does exactly the same:
IF ((roses == RED) AND (VIOLET == BLUE)) THEN PRINT "Life is Sweet" ELSE PRINT "I love you"
Now in the boolean expression, we have the subexpression
(VIOLET==BLUE)
but these are two different values and this is asking whether they are the same or not. It evaluates to true if they are the same and FALSE if they are different. It is therefore equivalent to FALSE so the whole expression becomes:
(roses==RED) AND FALSE
The original algorithm is equivalent to
IF ((roses == RED) AND FALSE) THEN PRINT "Life is Sweet" ELSE PRINT "I love you"
Now whatever X is a boolean expression (X & FALSE) will always evaluate to FALSE because it needs both to be TRUE for the whole to be TRUE. The whole boolean expression therefore simplifies to FALSE and the algorithm to:
IF (FALSE) THEN PRINT "Life is Sweet" ELSE PRINT "I love you"
Notice how this means it does not matter what colour the roses are at all. Whether roses are red, white, blue or something else, the algorithm result will not be affected.
The semantics of an IF statement is that it evaluates exactly one of its two statements. Where its test (boolean expression) evaluates to TRUE, it executes the first THEN branch (here the Life is Sweet branch) and ignores the other ELSE branch (the I love you branch). Where its test evaluates to FALSE it instead ignores the THEN branch completely and executes the ELSE branch.
Here the test is FALSE, so it ignores the THEN branch and is equivalent to the ELSE branch. The algorithm as a whole is exactly equivalent to the far simpler algorithm:
PRINT "I love you"
Going back to the poem, it is therefore logically completely equivalent to a poem I Love You
We have given a mathematical proof of love! The idea though is that only computer scientists with a formal semantics (ie maths meaning) of the pseudocode language used would see it!
Programming languages have lots of control structures, like if-statements and while loops, case-statements and for loops, method call and return, … but a famous research result in theoretical computer science (now called the structured program theorem) says you can do everything that it is possible to do with only three. All those alternatives are just for convenience. All you need is one way each to do sequence; one way to do selection, and one way to do iteration. If you have those you can build the structure needed to do any computation. In particular, you do not need a goto statement! We can explore what that means by just thinking about instructions to build Lego.
What do we mean by a control structure? Just some mechanism to decide the order that instructions must be done for an algorithm to work. Part of what makes a set of instructions an algorithm is that the order of instructions are precisely specified. Follow the instructions in the right order and the algorithm is guaranteed to work.
Goto
First of all, Lego instructions are designed to be really clear and easy to follow. The nice folk at Lego want anyone to be able to follow them, even a small child and manage to accurately build exactly the model shown on the box.
What they do not make use of is a Goto instruction, an arbitrary jump to another place, where you are told, for example, to move to Page 14 for the next instruction. That kind of jump from place to place is reserved for Fighting Fantasy Adventure Books, where you choose the path through the story. They jump you about precisely because the aim is for you to be lost in the myriad of potential stories that are possible. You just don’t do that if you want instructions to be easy to follow.
The structured program theorem provided the ammunition for arguing that goto should not be used in programming and instead structured programming (hence the theorem’s name) should be used instead. All it actually does is show it is not needed though, not that its use is worse, though the argument was eventually won, with some exceptions. For programs to be human-readable and maintainable it is best that they use forms of structured programming, and avoid the spaghetti programming structures that goto leads to..
Sequencing
The main kind of control structure in a booklet of Lego instructions is instead sequencing. Instructions follow one after the other. This is indicated by the pages of the booklet. On each page though the instructions are split into boxes that are numbered. The boxes and numbers are the essential part of the control structure. You build the Lego model in the order of the numbered boxes. The numbering provides a sequencing control structure. Programming languages usually just use the order of instructions down a page to indicate sequencing, sometimes separated by punctuation (like a semi-colon), though early languages used this kind of numbering. The point is the same, however it is done, it is just a mechanism to make clear the order that the instructions are followed one after another, i.e., sequencing.
Parallelism and time-slicing
However, with lego there is another control structure within those boxes that is not quite sequencing. Each box normally has multiple pieces to place with the position of each shown. The lego algorithm isn’t specifying the order those pieces are placed (any order will do). This is a kind of non-deterministic sequencing control structure. It is similar to a parallelism control structure in programming languages, as if you like building your Lego model together with others, then a different person could choose each piece and all place the piece together (parallelism). Alternatively, they could place the pieces one after the other in some random order (time-slicing) and always end up with the same final result once the box is completed.
Is this necessary though? The structured program theorem says not, and in this case it is relatively easy to see that it isn’t. The people writing the instruction booklet could have decided an order themselves and enforced it. Which order they chose wouldn’t matter. Any Lego instruction booklet could be converted to one using only sequencing without parallelism or time-slicing.
Iteration
Image by CS4FN after Lego instruction iteration
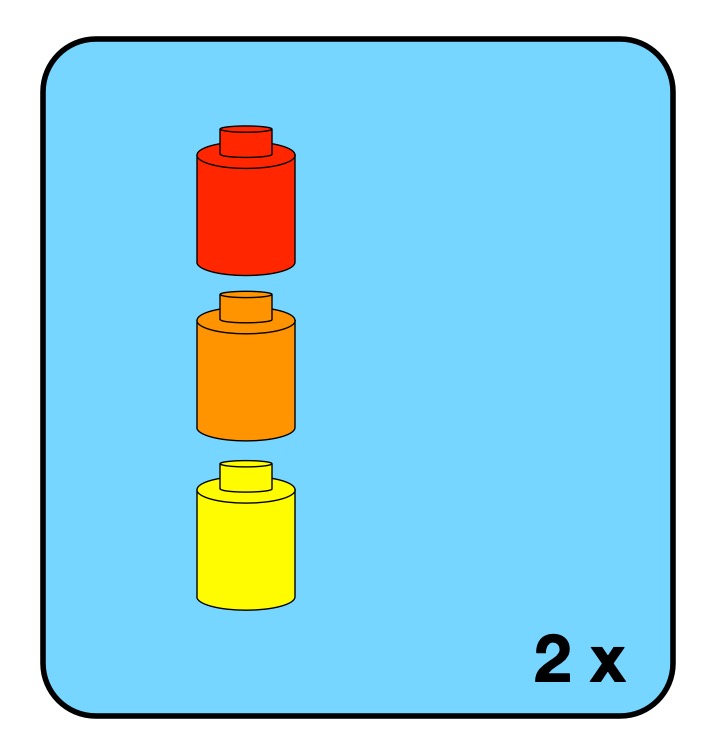
Iteration is just a way to repeat instructions or sub-programs. Lego instructions have a simplified form of repetition which is the equivalent of a simple for loop in programming. It just says that a particular box of instructions should be followed a fixed number of times (like 3 x meaning make this lego sub-build three times). With only this way of doing iteration lego instructions are not a totally general form of computation. There are algorithms that can’t be specified in Lego instructions. To be good enough to play the full role in the theorem, the iteration control structure has to have the capability to be unbounded. The decision to continue or not is made at the end of each iteration, You follow the instructions once, then decide if they should be followed again (and keep doing that). Having such a control structure would mean that at the point when you started to build the lego construct to be repeated, you would not necessarily know how many times that Lego construct was to be built. It’s possible to imagine Lego builds like this. For example, you might be building a fairytale castle made of modular turreted towers, where you can keep deciding whether to build another tower after each new tower is completed. until the castle is big enough. That would be an unbounded loop. An issue with unbounded loops is they could never terminate…you could be eternally damned to build Lego towers to eternity!
Selection
The final kind of control structure needed is selection. Selection involves having a choice of what instruction or subprogram to do next. This allows an algorithm to do different things depending on data input or the results of computation. As most lego sets involve building one specific thing, there isn’t much use of selection in Lego booklets.
However, some lego sets do have a simple form of selection. There are “3 in 1” sets where you can, for example, choose to make one of three animals by choosing one of three instruction booklets to follow at the start.
To be fully computationally general there would need to be choice possible at any point, in the way repetition can appear at any point in the booklet. It would need to be possible for any instruction or block of instructions to be prefigured by a test of whether they should be followed or not, with that test and arbitrary true/false question.
Again, such a thing is conceivable if more complex Lego builds were wanted. Building a fairytale castle you might include options to choose to build different kinds of turret on top of the towers, or choose different colours of bricks to make rainbow towers, or… If this kind of totally general choice was provided then no other kind of selection control structure would be needed. Having such instructions would provide a level of creativity between those of fixed sets to build one thing and the origianl idea of Lego as just blocks you could build anything from (the sets would need more bricks though!)
Sequence, Selection and Iteration is enough (but only if powerful enough)
So Lego instruction booklets do include the three kinds of control structure needed of sequence, selection and iteration. However, the versions used are not actually general enough for the structured control theorem to apply. Lego instructions with the control structures discussed are not powerful enough to be computationally complete, and describe all possible algorithms. More general forms are needed than found in normal Lego instructions to do that. In particular, a more general version of iteration is needed, as well as a verion of selection that can be used anywhere, and that includes a general purpose test. All programming languages have some powerful version of all three control structures. If they did not they could not be used as general purpose languages. There would be algorithms that could not be implemented in the language.
Just like programming languages, Lego instructions also use an extra kind of control structures that is not actually needed, It is there just for convenience, just like programming languages have lots of extra control structures just for convenience too.
Sadly then, Lego instructions, as found in the normal instruction booklets are not as general as a programming language. They do still provide a similar amount of fun though. Now, I must get back to building Notre Dame.
A perceptron winter: Winter image by Image by Nicky ❤️🌿🐞🌿❤️ from Pixabay. Perceptron and all other image by CS4FN.
Back in the 1960s there was an AI winter…after lots of hype about how Artificial Intelligence tools would soon be changing the world, the hype fell short of the reality and the bubble burst, funding disappeared and progress stalled. One of the things that contributed was a simple theoretical result, the apparent shortcomings of a little device called a perceptron. It was the computational equivalent of an artificial brain cell and all the hype had been built on its shoulders. Now, variations of perceptrons are the foundation of neural networks and machine learning tools which are taking over the world…so what went wrong in the 1960s? A much misunderstood mathematical result about what a perceptron can and can’t do was part of the problem!
The idea of a perceptron dates back to the 1940s but Frank Rosenblatt, a researcher at Cornell Aeronautical Laboratory, first built one in 1958 and so popularised the idea. A perceptron can be thought of as a simple gadget, or as an algorithm for classifying things. The basic idea is it has lots of inputs of 0 or 1s and one output, also of 0 or 1 (so equivalent to taking true / false inputs and returning a true / false output). So for example, a perceptron working as a classifier of whether something was a mammal or not, might have inputs representing lots of features of an animal. These would be coded as 1 to mean that feature was true of the animal or 0 to mean false: INPUT: “A cow gives birth to live young” (true: 1), “A cow has feathers” (false: 0), “A cow has hair” (true: 1), “A cow lays eggs” (false: 0), “etc. OUTPUT: (true: 1) meaning a cow has been classified as a mammal.
A perceptron makes decisions by applying weightings to all the inputs that increase the importance of some, and lesson the importance of others. It then adds the results together also adding in a fixed value, bias. If the sum it calculates is greater then or equal to 0 then it outputs 1, otherwise it outputs 0. Each perceptron has different values for the bias and the weightings, depending on what it does. A simple perceptron is just computing the following bit of code for inputs in1, in2, in3 etc (where we use a full stop to mean multiply):
IF bias + w1.in1 + w2.in2 + w3.in3 ... >= 0
THEN OUTPUT O
ELSE OUTPUT 1
Because it uses binary (1s and 0s), this version is called a binary classifier. You can set a perceptron’s weights, essentially programming it to do a particular job, or you can let it learn the weightings (by applying learning algorithms to the weightings). In the latter case it learns for itself the right answers. Here, we are interested in the fundamental limits of what perceptrons could possibly learn to do, so do not need to focus on the learning side just on what a perceptron’s limits are. If we can’t program it to do something then it can’t learn to do it either!
Machines made of lots of perceptrons were created and experiments were done with them to show what AIs could do. For example, Rosenblatt built one called Tobermory with 12,000 weights designed to do speech recognition. However, you can also explore the limits of what can be done computationally through theory: using maths and logic, rather than just by invention and experiments, and that kind of theoretical computer science was what others did about perceptrons. A key question in theoretical computer science about computers is “What is computable?” Can your new invention compute anything a normal computer can? Alan Turing had previously proved an important result about the limits of what any computer could do, so what about an artificial intelligence made of perceptrons? Could it learn to do anything a computer could or was it less powerful than that?
As a perceptron is something that takes 1s and 0s and returns a 1 or 0, it is a way of implementing logic: AND gates, OR gates, NOT gates and so on. If it can be used to implement all the basic logical operators then a machine made of perceptrons can do anything a computer can do, as computers are built up out of basic logical operators. So that raises a simple question, can you actually implement all the actual logical operators with perceptrons set appropriately. If not then no perceptron machine will ever be as powerful as a computer made of logic gates! Two of the giants of the area Marvin Minsky and Seymour Papert investigated this. What they discovered contributed to the AI winter (but only because the result was misunderstood!)
Let us see what it involves. First, can we implement an AND gate with appropriate weightings and bias values with a perceptron? An AND gate has the following truth table, so that it only outputs 1 if both its inputs are 1:
Truth table for an AND gate
So to implement it with a perceptron, we need to come up with positive or negative number for, bias, and other numbers for w1 and w2, that weight the two inputs. The numbers chosen need to lead to it giving output 1 only when the two inputs (in1 and in2) are 1 and otherwise giving output, 0.
See if you can work out the answer before reading on.
A perceptron for an AND gate needs values set for bias, w1 and w2
It can be done by setting the value of b to -2 and making both weightings, w1 and w2, value 1. Then, because the two inputs, in1, and in2 can only be 1 or 0, it takes both inputs being 1 to overcome b’s value of -2 and so raise the sum up to 0:
So far so good. Now, see if you can work out weightings to make an OR gate and a NOT gate.
Truth table for an OR gateTruth table for a NOT gate
It is possible to implement both OR and NOT gate as a perceptron (see answers at the end).
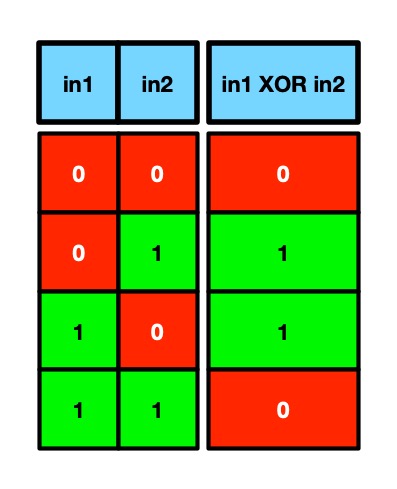
However, Minsky and Papert proved that it was impossible to create another kind of logical operator, an XOR gate, with any values of bias and weightings in a perceptron. This a logic gate that has output 1 if its inputs are different, and outputs 0 if its inputs are the same.
Truth table for an XOR gate
Can you prove it is impossible?
They had seemingly shown that a perceptron could not compute everything a computer could. Perceptrons were not as expressive so not as powerful (and never could be as powerful) as a computer. There were things they could never learn to do, as there were things as simple as an XOR gate that they could not represent. This led some to believe the result meant AIs based on perceptrons were a dead end. It was better to just work with traditional computers and traditional computing (which by this point were much faster anyway). Along with the way that the promises of AI had been over-hyped with exaggerated expectations and the applications that had emerged so far had been fairly insignificant, this seemingly damming theoretical blow on top of all that led to funding for AI research drying up.
However, as current machine learning tools show, it was never that bad. The theoretical result had been misunderstood, and research into neural networks based on perceptrons eventually took off again in the 1990s
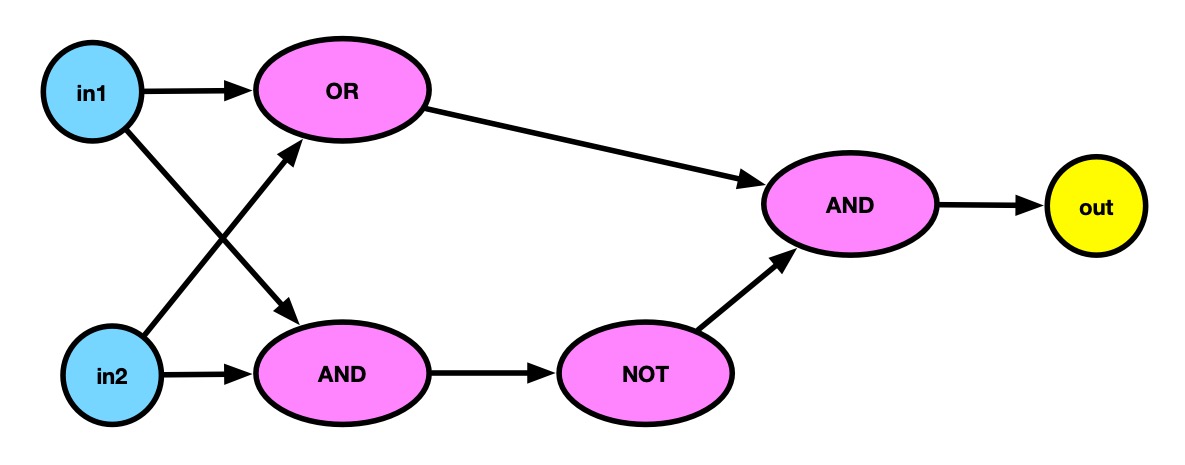
Minsky and Papert’s result is about what a single perceptron can do, not about what multiple ones can do together. More specifically, if you have perceptrons in a single layer, each with inputs just feeding its own outputs, the theoretical limitations apply. However, if you make multiple layers of perceptrons, with the outputs of one layer of perceptrons feeding into the next, the negative result no longer applies. After all, we can make AND, OR and NOT gates from perceptrons, and by wiring them together so the outputs of one are the inputs of the next one, then we can build an XOR gate just as we can with normal logic gates!
An XOR gate from layers of perceptrons set as AND, OR and NOT operators
We can therefore build an XOR gate from perceptrons. We just need multi-layer perceptrons, an idea that was actually known about in the 1960s including by Minsky and Papert. However, without funding, making further progress became difficult and the AI winter started where little research was done on any kind of Artificial Intelligence, and so little progress was made.
The theoretical result about the limits of what perceptrons could do was an important and profound one, but the limitations of the result needed to be understood too, and that means understanding the assumptions it is based on (it is not about multi-layer perceptrons. Now AI is back, though arguably being over-hyped again, so perhaps we should learn from the past!. Theoretical work on the limits of what neural networks can and can’t do is an active research area that is as vital as ever. Let’s just make sure we understand what results mean before we jump to any conclusions. Right now theoretical results about AI need more funding not a new winter!
– Paul Curzon, Queen Mary University of London
This article is based on a introductory segment of a research seminar on the expressive power of graph neural networks by Przemek Walega, Queen Mary University of London, October 2025.
Computer Scientists talk about “Syntactic Sugar” when talking about programming languages. But in what way might a program be made sweet? It is all about how necessary a feature of a language is, and the idea and phrase was invented by Computer Scientist and gay activist, Peter Landin. He realised it made it easier to define the meaning of languages in logic and made the definitions more elegant.
Peter Landin was involved in the development of several early and influential programming languages but also a pioneer of the use of logic to define exactly what each construct of a programming language did: the language’s “semantics”. He realised there was a fundamental difference between different parts of a language. Some were absolutely fundamental to the language. If you removed them then programs would have to be written in a different way, if at all, as a result. Remove the assignment construct that allows a program to change the value of variables, for example, and there are things your programs can no longer do, or at least it would need to do it in very different way. Remove the feature that allows someone to write i++ instead of i = i + 1, on the other hand, and nothing much changes about how you write code. They were just abbreviations for common uses of the more core things.
As another example, suppose you didn’t like using curly brackets to start and end blocks of code (perhaps having learnt to program using Pascal) then if programming in C or Java you could add a layer of syntactic sugar by replacing { by BEGIN and } by END. Your programs might look different and make you feel happier, but were not really any different.
Peter called these kinds of abbreviations “syntactic sugar”. They were superficial, just there to make the syntax (the way things were written at the level of spelling and punctuation) a little bit nicer for the programmers: sometimes more readable, sometimes just needing less typing.
It is now recognised, of course, that writing readable code is a critically important part of programming. Code has to be maintainable: easily understood and modified by others long after it was written. Well thought out syntactic sugar can help with this as well as making it easier to avoid mistakes when writing code in the first place. For example, syntactic sugar is used in many languages to give special syntax to core datatypes, where they are called sugared types. Common example include using quotes to represent a String value like “abc” or square brackets like [1,2,3] to stand for an array value, rather than writing out the underpinning function calls of the core language to construct a value.
People now sometimes deride the idea of syntactic sugar, but it had a clear use for Peter beyond just readability. He was interested in logically defining languages: saying in logic exactly what each construct meant. The syntactic sugar distinction made his life doing that easier. The fundamental things were the things that he had to define directly in logic. He had to work out exactly what the semantics of each was and how to say what they meant mathematically. Syntactic sugar could be defined just by adding rewrite rules that convert the syntactic sugar to the core syntax. i++, for example does not need to be defined logically, just converted to i = i + 1 to give its meaning. If assignment was defined in terms of logic then the abbreviation is ultimately too as a result.
Peter discussed this in relation to treating a kind of logic called the lambda calculus as the basis for a language. Lambda Calculus is a logic based on functions. Everything consists of lambda expressions, though he was looking at a version which included arithmetic too. For example, in this logic, the expression:
(λn.2+n)
defines a function that takes a value n and returns the value resulting from adding 2 to that value. Then the expression:
(λn.2+n) [5]
applies that function to the value 5, meaning 5 is substituted for the n that comes after the lambda, so it simplifies to 2+5 or further to 7. Lambda expressions, therefore, have a direct equivalence to function call in a programming language. The lambda calculus has a very simple and precise mathematical meaning too, in that any expression is just simplified by substituting values for variables as we did to get the answer 7 above. It could be used as a programming language in itself. Logicians (and theoretical computer scientists) are perfectly happy reading lambda calculus statements with λ’s, but Peter realised that as a programming language it would be unreadable to non-logicians. However with a simple change, adding syntactic sugaring, it could be made much more readable. This just involved replacing the Greek letter λ by the word “where” and altering the order and throwing in an = sign..
Now instead of writing
(λn.2+n) [5]
in his programming language you would write
2 + n where n = 5
Similarly,
(λn.3n+2) [a+1]
became
3n+2 where n = a + 1
This made the language much more readable but did not complicate the task of defining the semantics. It is still just directly equivalent to the lambda calculus so the lambda calculus can still be used to define its semantics in a simple way (just apply those transformations backwards). Overall this work showed that the group of languages called functional programming languages could be defined in terms of lambda calculus in a very elegant way.
Syntactic sugar is at one level a fairly trivial idea. However, in introducing it in the context of defining the semantics of languages it is very powerful. Take the idea to its extreme and you define a very small and elegant core to your language in logic. Then everything else is treated as syntactic sugar with minimal work to define it as rewrite rules. That makes a big difference in the ease of defining a programming language as well as encouraging simplicity in the design. It was just one of the ways that Peter Landin added elegance to Computer Science.
Thousands of programming languages have been invented in the many decades since the first. But what makes a good language? A key idea behind language design is that they should make it easy to write complex algorithms in simple and elegant ways. It turns out that logic is key to that. Through his work on programming language design, Peter Landin as much as anyone, promoted both elegance and the linked importance of logic in programming.
Peter was an eminent Computer Scientist who made major contributions to the theory of programming languages and especially their link to logic. However, he also made his mark in his stand against war, and support of the nascent LGBTQ+ community in the 1970s as a member of the Gay Liberation Front. He helped reinvigorate the annual Gay Pride marches as a result of turning his house into a gay commune where plans were made. It’s as a result of his activism as much as his computer science that an archive of his papers has been created in the Oxford Bodleian Library.
However, his impact on computer science was massive. He was part of a group of computing pioneers aiming to make programming computers easier, and in particular to move away from each manufacturer having a special programming language to program their machines. That approach meant that programs had to be rewritten to work on each different machine, which was a ridiculous waste of effort! Peter’s original contribution to programming languages was as part of the team who developed the programming language, ALGOL which most modern programming languages owe a debt to.
ALGOL included the idea of recursion, allowing a programmer to write procedures and functions that call themselves. This is a very mathematically elegant way to code repetition in an algorithm (the code of the function is executed each time it calls itself). You can get an idea of what recursion is about by standing between two mirrors. You see repeated versions of your reflection, each one smaller than the last. Recursion does that with problem solving. To solve a problem convert it to a similar but smaller version of the same problem (the first reflection). How do you solve that smaller problem? In the same way, as a smaller version of the same problem (the second reflection)… You keep solving those similar but smaller problems in the same way until eventually the problem is small enough to be trivial and so solved. For example, you can program a factorial method (multiplying all numbers from 1 to n together),in this way. You write that to compute factorial of a number, n, it just calls itself and computes the factorial of (n-1). It just multiply that result by n to get the answer. In addition you just need a trivial case eg that factorial of 1 is just 1.
Peter was an enthusiastic and inspirational teacher and taught ALGOL to others. This included teaching one of the other, then young but soon to be great, pioneers of Programming Theory, Tony Hoare. Learning about recursion led Hoare to work out a way, using recursion, to finally explain the idea that made his name in a simple and elegant way: the fast sorting algorithm he invented called Quicksort. The ideas included in ALGOL had started to prove their worth.
The idea of including recursion in a programming language was part of the foundation for the idea of functional programming languages. They are mathematically pure languages that use recursion as the way to repeat instructions. The mathematical purity makes them much easier to understand and so write correct programs in. Peter ran with the idea of programming in this way. He showed the power that could be derived from the fact that it was closely linked to a kind of logic called the Lambda Calculus, invented by Alonso Church. The Lambda Calculus is a logic built around mathematical functions. One way to think about it is that it is a very simple and pure way to describe in logic what it means to be a mathematical function – as something that takes arguments and does computation on them to give results. This Church showed was a way to define all possible computation just as Turing’s Turing machine is. It provides a simple way to express anything that can be computed.
Peter showed that the Lambda Calculus could be used as a way to define programming languages: to define their “semantics” (and so make the meaning of any program precise).
Having such a precise definition or “semantics” meant that once a program was written it would be sure to behave the same way whatever actual computer it ran on. This was a massive step forward. To make a new programming language useful you had to write compilers for it: translators that convert a program written in the language to a low level one that runs on a specific machine. Programming languages were generally defined by the compiler up till then and it was the compiler that determined what a program did. If you were writing a compiler for a new machine you had to make sure it matched what the original compiler did in all situations … which is very hard to do.
So having a formal semantics, a mathematical description of what a compiler should do, really makes a difference. It means anyone developing a new compiler for a different machines can ensure the compiler matches that semantics. Ultimately, all compilers behave the same way and so one program running on two different manufacturer’s machines are guaranteed to behave the same way in all situations too.
Peter went on to invent the programming language ISWIM to illustrate some of his ideas about the way to design and define a programming language. ISWIM stands for “If you See What I Mean”. A key contribution of ISWIM was that the meaning of the language was precisely defined in logic following his theoretical work. The joke of the name meant it was logic that showed what he meant, very precisely! ISWIM allowed for recursive functions, but also allowed recursion in the definition of data structures. For example, a List is built from a List with a new node on the end. A Tree is built from two trees forming the left and right branches of a new node. They are defined in terms of themselves so are recursive.
Building on his ideas around functional programming, Peter also invented something he called the SECD machine (named after its components: a Stack, Environment, Control and Dump). It effectively implements the Lambda calculus itself as though it is a programming language.ISWIM provided a very simple but useful general-purpose low level language. It opened up a much easier way to write compilers for functional programming languages for different machines. Just one program needed to be written that compiled the language into SECD. Then you had a much simpler job of writing a compiler to convert from the low level SECD language to the low level assembly language of each actual computer. Even better, once written, that low level SECD compiler could be used for different functional programming languages on a single machine. In SECD, Peter also solved a flaw in ALGOL that prevented functions being fully treated as data. Functions as Data is a powerful feature of the best modern programming languages. It was the SECD design that first provided a solution. It provided a mechanism that allowed languages to pass functions as arguments and return them as results just as you could do with any other kind of data without problem.
In the later part of his life Peter focussed much more on his work supporting the LGBTQ+ community having decided that Computer Science was not doing the good for humanity he once hoped. Instead, he thought it was just supporting companies making profit, ahead of the welfare of people. He decided that he could do more good as part of the LGBTQ+ community. Since his death there has been an acceleration in the massing of wealth by technology companies, whereas support for diversity has made a massive difference for good, so in that he was prescient. His contributions have certainly, though, provided a foundation for better software, that has changed the way we live in many ways for the better. Because of his work they are less likely to cause harm because of programming mistakes, for example, so in that at least he has done a great deal of good.