‘How do robots eat pizza?’… ‘One byte at a time’. Computational Humour is real, but it’s not jokes about computers, it’s computers telling their own jokes.
Computers can create art, stories, slogans and even magic tricks. But can computers perform themselves? Can robots invent their own jokes? Can they tell jokes?
Combining Artificial Intelligence, computational linguistics and humour studies (yes you can study how to be funny!) a team of Scottish researchers made an early attempt at computerised standup comedy! They came up with Standup (System to Augment Non Speakers Dialogue Using Puns): a program that generates riddles for kids with language difficulties. Standup has a dictionary and joke-building mechanism, but does not perform, it just creates the jokes. You will have to judge for yourself as to whether the puns are funny. You can download the software from here. What makes a pun funny? It is a about the word having two meanings at exactly the same time in a sentence. It is also about generating an expectation that you then break: a key idea about what is at the core of creativity too.
A research team at Virginia Tech in the US created a system that started to learn about funny pictures. Having defined a ‘funniness score’ they created a computational model for humorous scenes, and trained it to predict funniness, perhaps with an eye to spotting pics for social media posting, or not.
But are there funny robots out there? Yes! RoboThespian programmed by researchers at Queen Mary University of London, and Data, created by researchers at Carnegie Mellon University are both robots programmed to do stand-up comedy. Data has a bank of jokes and responds to audience reaction. His developers don’t actually know what he will do when he performs, as he is learning all the time. At his first public gig, he got the crowd laughing, but his timing was poor. You can see his performance online, in a TED Talk.
RoboThespian did a gig at the London Barbican alongside human comedians. The performance was a live experiment to understand whether the robot could ‘work the audience’ as well as a human comedian. They found that even relatively small changes in the timing of delivery make a big difference to audience response.
What have these all got in common? Artificial Intelligence, machine learning and studies to understand what humour actually is, are being combined to make something that is funny. Comedy is perhaps the pinnacle of creativity. It’s certainly not easy for a human to write even one joke, so think how hard it is distill that skill into algorithms and train a computer to create loads of them.
You have to laugh!
Jane Waite, Queen Mary University of London, Summer 2017
Based on a 2016 talk by Sabine Hauert at the Royal Society
Sabine Hauert is a swarm engineer. She is fascinated by the idea of making use of swarms of robots. Watch a flock of birds and you see that they have both complex and beautiful behaviours. It helps them avoid predators very effectively, for example, so much so that many animals behave in a similar way. Predators struggle to fix on any one bird in all the chaotic swirling. Sabine’s team at the University of Bristol are exploring how we can solve our own engineering problems: from providing communication networks in a disaster zone to helping treat cancer, all based on the behaviours of swarms of animals.
Sabine realised that flocks of birds have properties that are really interesting to an engineer. Their ability to scale is one. It is often easy to come up with solutions to problems that work in a small ‘toy’ system, but when you want to use it for real, the size of the problem defeats you. With a flock, birds just keep arriving, and the flock keeps working, getting bigger and bigger. It is common to see thousands of Starlings behaving like this – around Brighton Pier most winter evenings, for example. Flocks can even be of millions of birds all swooping and swirling together, never colliding, always staying as a flock. It is an engineering solution that scales up to massive problems. If you can build a system to work like a flock, you will have a similar ability to scale.
Flocks of birds are also very robust. If one bird falls out of the sky, perhaps because it is caught by a predator, the flock itself doesn’t fail, it continues as if nothing happened. Compare that to most systems humans create. Remove one component from a car engine and it’s likely that you won’t be going anywhere. This kind of robustness from failure is often really important.
Swarms are an example of emergent behaviour. If you look at just one bird you can’t tell how the flock works as a whole. In fact, each is just following very simple rules. Each bird just tracks the positions of a few nearest neighbours using that information to make simple decisions about how to move. That is enough for the whole complex behaviour of the flock to emerge. Despite all that fast and furious movement, the birds never crash into each other. Fascinated, Sabine started to explore how swarms of robots might be used to solve problems for people.
Her first idea was to create swarms of flying robots to work as a communications network, providing wi-fi coverage in places it would otherwise be hard to set up a network. This might be a good solution in a disaster area, for example, where there is no other infrastructure, but communication is vital. You want it to scale over the whole disaster area quickly and easily, and it has to be robust. She set about creating a system to achieve this.
The robots she designed were very simple, fixed wing, propellor-powered model planes. Each had a compass so it knew which direction it was pointing and was able to talk to those nearest using wi-fi signals. It could also tell who its nearest neighbours were. The trick was to work out how to design the behaviour of one bird so that appropriate swarming behaviour emerged. At any time each had to decide how much to turn to avoid crashing into another but to maintain the flock, and coverage. You could try to work out the best rules by hand. Instead, Sabine turned to machine learning.
“Throwing those flying robots and seeing them flock was truly magical”
The idea of machine learning is that instead of trying to devise algorithms that solve problems yourself, you write an algorithm for how to learn. The program then learns for itself by trial and error the best solution. Sabine created a simple first program for her robots that gave them fairly random behaviour. The machine learning program then used a process modelled on evolution to gradually improve. After all evolution worked for animals! The way this is done is that variations on the initial behaviour are trialled in simulators and only the most successful are kept. Further random changes are made to those and the new versions trialled again. This is continued over thousands of generations, each generation getting that little bit better at flocking until eventually a behaviour of individual robots results that leads to them swarming together.
Sabine has now moved on to to thinking about a situation where swarms of trillions of individuals are needed: nanomedicine. She wants to create nanobots that are each smaller than the width of a strand of hair and can be injected into cancer patients. Once inside the body they will search out and stick themselves to tumour cells. The tumour cells gobble them up, at which point they deliver drugs directly inside the rogue cell. How do you make them behave in a way that gives the best cancer treatment though? For example, how do you stop them all just sticking to the same outer cancer cells? One way might be to give them a simple swarm behaviour that allows them to go to different depths and only then switch on their stickiness, allowing them to destroy all the cancer cells. This is the sort of thing Sabine’s team are experimenting with.
Swarm engineering has all sorts of other practical applications, and while Sabine is leading the way, some time soon we may need lots more swarm engineers, able to design swarm systems to solve specific problems. Might that be you?
Paul Curzon, Queen Mary University of London
Explore swarm behaviour using the Oxford Turtle system [EXTERNAL] (click the play button top centre) to see how to run a flocking simulation as well as program your own swarms.
Telepathy is the supposed Extra Sensory Perception ability to read someone else’s mind at a distance. Whilst humans do not have that ability, brain-computer interaction researchers at Stanford have just made the high tech version a virtual reality.
It has long been know that by using brain implants or electrodes on a person’s head it is possible to tell the difference between simple thoughts. Thinking about moving parts of the body gives particularly useful brain signals. Thinking about moving your right arm, generates different signals to thinking about moving your left leg, for example, even if you are paralysed so cannot actually move at all. Telling two different things apart is enough to communicate – it is the basis of binary and so how all computer-to-computer communication is done. This led to the idea of the brain-computer interface where people communicate with and control a computer with their mind alone.
Stanford researchers made a big step forward in 2017, when they demonstrated that paralysed people could move a cursor on a screen by thinking of moving their hands in the appropriate direction. This created a point and click interface – a mind mouse – for the paralysed. Impressively, the speed and accuracy was as good as for people using keyboard applications
Stanford researchers have now gone a step even further and used the same idea to turn mental handwriting into actual typing. The person just thinks of writing letters with an imagined pen on imagined paper, the brain-computer interface then picks up the thoughts of subtle movements and the computer converts them into actual letters. Again the speed and accuracy is as good as most people can type. The paralysed participant concerned could communicate 18 words a minute and made virtually no mistakes at all: when the system was combined with auto-correction software, as we now all can use to correct our typing mistakes, it got letters right 99% of the time.
The system has been made possible by advances in both neuroscience and computer science. Recognising the letters being mind-written involves distinguishing very subtle differences in patterns of neurons firing in the brain. Recognising patterns is however, exactly what Machine Learning algorithms do. They are trained on lots of data and pick out patterns of similar data. If told what letter the person was actually trying to communicate then they can link that letter to the pattern detected. Here each letter will not lead to exactly the same pattern of brain signals firing each time, but they will largely clump together,. Other letters will also group but with slightly different patterns of firings. Once trained, the system works by taking the pattern of brain signals just seen and matching it to the nearest clumping pattern. The computer then guesses that the nearest clumping is the letter being communicated. If the system is highly accurate, as this one was at 94% (before autocorrection), then it means the patterns of most letters are very distinct. A letter being mind-written rarely fell into a brain pattern gap, which would have meant that letter could as easily have been the pattern of one letter as the other.
So a computer based “telepathy” is possible. But don’t expect us all to be able to communicate by mind alone over the internet any time soon. The approach involves having implants surgically inserted into the brain: in this case two computer chips connecting to your brain via 100 electrodes. The operation is a massive risk to take, and while perhaps justifiable for someone with a problem as severe as total paralysis, it is less obvious it is a good idea for anyone else. However, this shows at least it is possible to communicate written messages by mind alone, and once developed further could make life far better for severely disabled people in the future.
Yet again science fiction is no longer fantasy, it is possible, just not in the way the science fiction writers perhaps originally imagined by the power of a person’s mind alone.
Paul Curzon, Queen Mary University of London, Spring 2021
New technology can have unforeseen effects. The Law in particular can sometimes struggle to keep up, but for the IT savvy lawyer that can mean opportunity. For example, one bunch of lawyers realised that the way money moves round the world electronically could give their clients the edge. Nanoseconds are all it takes. As a result, a bunch of New York nanoseconds gave Judges in the Southern district court of the city a real headache.
Different countries have different laws. That means lawyers will go out of their way to apply the law for their clients in the right country. It can make all the difference. Unlike some other countries US maritime law allows a person to freeze a person’s assets, even before a decision has been reached, when there is a maritime claim against them. For example, if a merchant hasn’t been paid for a shipload of cargo, or if a shipyard hasn’t been paid for ship repairs, then they can use this rule to freeze the defaulter’s money. Otherwise a win, when it comes, could be rather hollow, with the money long placed out of reach. The only trouble for the lawyers is that the money has to be in the US for the US law to apply.
Frozen money
That is where the technology comes in. Bankers don’t ship physical money from country to country, it’s all done electronically now… A consequence of the way the banking system was set up is that dollar transactions had to pass through the US banking centre in Manhattan as the money has to move from place to place. That’s an easy thing to require data to do in the age of the Internet. It only spends a fraction of a second in New York before it jumps on somewhere else. The law, of course, makes no distinction over shrinking timescales in which computers make things happen. A prepared lawyer can have the money frozen in that instant as just at that moment it is in the US.
That was great for people wanting to hold up money. It was a nightmare for the New York judges, though. Once the lawyers caught on about those nanoseconds the work started stacking up for the judges. All those fractions of a second added up to hours of the Judges’ time granting permission for the money to be seized. Every day the poor New York judges had to process hundreds and hundreds of requests, just in case some disputed money happened to pass through that day. To seize the money, it wasn’t enough just to put in a request and wait, ready to pounce when the money lands in Manhattan. Instead, just like a Spider re-spinning its web every morning, the trap had to be renewed daily. To do that the lawyers had to serve the bank daily with notice that if any money passed through that day it had to be stopped in its high speed tracks.
New technology constantly brings up new problems like this, when old laws or procedures are found to be wanting when technology changes the way things are done: changes things far beyond the imagination of those who drafted the laws. Just as technology never stands still, neither does the law…or the IT savvy lawyer.
Paul Curzon, Queen Mary University of London, Summer 2017, updated Spring 2021
Subscribe to be notified whenever we publish a new post to the CS4FN blog.
This blog is funded by EPSRC on research agreement EP/W033615/1.
The great Tudor and Stuart philosopher Sir Francis Bacon was a scientist, a statesman and an author. He was also a pretty decent computer scientist. He published* a new form of cipher, now called Bacon’s Cipher, invented when he was a teenager. Its core idea is the foundation for the way all messages are stored in computers today.
The Tudor and Stuart eras were a time of plot and intrigue. Perhaps the most famous is the 1605 Gunpowder plot where Guy Fawkes tried to assassinate King James I by blowing up the Houses of Parliament. Secrets mattered! In his youth Bacon had worked as a secret agent for Elizabeth I’s spy chief, Walsingham, so knew all about ciphers. Not content with using those that existed he invented his own. The one he is best remembered for was actually both a cipher and a form of steganography. While a cipher aims to make a message unreadable, steganography is the science of secret writing: disguising messages so no one but the recipient knows there is a message there at all.
A Cipher …
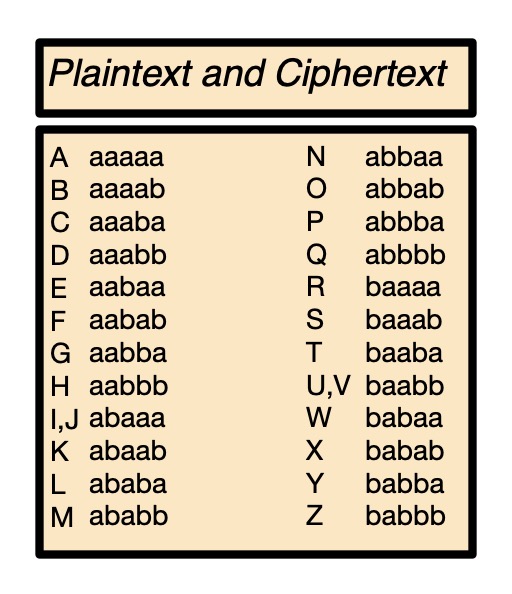
Bacon’s method came in two parts. The first was a substitution cipher, where different symbols are substituted for each letter of the alphabet in the message. This idea dates back to Roman times. Julius Caesar used a version, substituting each letter for a letter from a fixed number of places down the alphabet (so A becomes E, B becomes F, and so on). Bacon’s key idea was to replace each letter of the alphabet with, not a number or letter, but it’s own series of a’s and b’s (see the cipher table). The Elizabethan alphabet actually had only 24 letters so I and J have the same code as do U and V as they were interchangeable (J was the capital letter version of i and similarly for U and v).
In Bacon’s cipher everything is encoded in two symbols, so it is a binary encoding. The letters a and b are arbitrary. Today we would use 0 and 1. This is the first use of binary as a way to encode letters (in the West at least). Today all text stored in computers is represented in this way – though the codes are different – it is all Unicode is. It allocates each character in the alphabet with a binary pattern used to represent it in the computer. When the characters are to be displayed, the computer program just looks up which graphic pattern (the actual symbol as drawn) is linked to that binary pattern in the code being used. Unicode gives a binary pattern for every symbol in every human language (and some alien ones like Klingon).
Image by CS4FN
Steganography
The second part of Bacon’s cipher system was Steganography. Steganography dates back to at least the Greeks, who supposedly tattooed messages on the shaved heads of slaves, then let their hair grow back before sending them as both messenger and message. The binary encoding of Bacon’s cipher was vital to make his steganography algorithm possible. However, the message was not actually written as a’s and b’s. Bacon realised that two symbols could stand for any two things. If you could make the difference hard to spot, you could hide the messages. Bacon invented two ways of handwriting each letter of the alphabet – two fonts. An ‘a’ in the encoded message meant use one font and a ‘b’ meant use the other. The secret message could then be hidden inside an innocent one. The letters written were no longer the message, the message was in the font used. As Bacon noted, once you have the message in binary you could think of other ways to hide it. One way used was with capital and lower-case letters, though only using the first letter of words to make it less obvious.
Suppose you wanted to hide the message “no” in the innocuous message ‘hello world’. The message ‘no’ becomes ‘abbaa abbab’. So far this is just a substitution cipher. Next we hide it in, ‘hello world’. Two different kinds of fonts are those with curls on the tails of letters known as serif fonts and like this one and those without curls known as sans serif fonts and like this one. We can use a sans serif font to represent an ‘a’ in the coded message, and a serif font to represent ‘b’. We just alternate the fonts following the pattern of the a’s and b’s: ‘abbaa abbab’. The message becomes
Image by CS4FN
sans serif, serif, serif, sans serif, sans serif, sans serif, serif, serif, sans serif, serif.
Using those fonts for our message we get the final mixed font message to send:
Bacon the polymath
Bacon is perhaps best known as one of the principal advocates for rigorous science as a way of building up knowledge. He argued that scientists needed to do more than just come up with theories of how the world worked, and also guard against just seeing the results that matched their theories. He argued knowledge should be based on careful, repeated observation. This approach is the basis of the Scientific Method and one of the foundation stones of modern science.
Bacon was also a famous writer of the time, and one of many authors who has since been suggested as the person who wrote William Shakespeare’s plays. In his case it is because they claim to have found secret messages hidden in the plays in Bacon’s code. The idea that someone else wrote Shakespeare’s plays actually started just because some upper class folk with a lack of imagination couldn’t believe a person from a humble background could turn themselves into a genius. How wrong they were!
Paul Curzon, Queen Mary University of London, Autumn 2017
*Thanks to Pete Langman, whose PhD was on Francis Bacon, for pointing out a mistake in the original version of this blog where I suggested the cipher was published in, 1605, the year of the Gun Powder plot. It was actually first published in 1623 in De augmentis which was a translation/enlargement of his 1605 Advancement of Learning.
He also pointed out that Bacon conceived the idea while working with Elizabethan spymaster, Walsingham’s cipher expert at the time of the Babington plot to assasinate Elizabeth I, Thomas Phileppes, and Mary, Queen of Scots’ jailer, Amias Paulet. Bacon also claimed the cipher was never broken!
Subscribe to be notified whenever we publish a new post to the CS4FN blog.
This blog is funded by EPSRC on research agreement EP/W033615/1.
Suppose you want to send messages as fast as possible. What’s the best way to do it? That is what Polina Bayvel, a Professor at UCL has dedicated her research career to: exploring the limits of how fast information can be sent over networks. It’s not just messages that it’s about nowadays of course, but videos, pictures, money, music, books – anything you can do over the Internet.
Send a text message and it arrives almost instantly. Sending message hasn’t always been that quick, though. The Greeks used runners – in fact the Marathon athletic event originally commemorated a messenger who supposedly ran from a battlefield at Marathon to Athens to deliver the message “We won” before promptly dying. The fastest woman in the world at the time of writing, 2011, Paula Radcliffe, at her quickest could deliver a message a marathon distance away in 2 hours 15 minutes and 25 seconds (without dying!) … ( now in 2020, Brigid Kosgei, a minute or so faster).
Horses improved things (and the Greeks in fact normally used horseback messengers, but hey it was a good story). Unfortunately, even a horse can’t keep up the pace for hundreds of miles. The Pony Express pushed horse technology to its limits. They didn’t create new breeds of genetically modified fast horses, or anything like that. All it took was to create an organised network of normal ones. They set up pony stations every 10 miles or so right across North America from Missouri to Sacramento. Why every 10 miles? That’s the point a galloping horse starts to give up the ghost. The mail came thundering in to each station and thundered out with barely a break as it was swapped to a new fresh pony.
The pony express was swiftly overtaken by the telegraph. Like the switch to horses, this involved a new carrier technology – this time copper wire. Now the messages had to be translated first though, here into electrical signals in Morse code. The telegraph was followed by the telephone. With a phone it seems like you just talk and the other person just hears but of course the translation of the message into a different form is still happening. The invention of the telephone was really just the invention of a way to turn sound into an electrical code that could be sent along copper cables and then translated back again.
The Internet took things digital – in some ways that’s a step back towards Morse code. Now, everything, even sound and images, are turned into a code of ones and zeros instead of dots and dashes. In theory images could of course have been sent using a telegraph tapper in the same way…if you were willing to wait months for the code of the image to be tapped in and then decoded again. Better to just wait for computers that can do it fast to be invented.
In the early Internet, the message carrier was still good old copper wire. Trouble is, when you want to send lots of data, like a whole movie, copper wire and electricity are starting to look like the runners must have done to horse riders: slow out-of-date technology. The optical fibre is the modern equivalent of the horse. They are just long thin tubes of glass. Instead of sending pulses of electricity to carry the coded messages, they now go on the back of a pulse of light.
Up to this point it’s been mainly men taking the credit, but this is where Polina’s work comes in. She is both exploring the limits of what can be done with optical fibres in theory and building ever faster optical networks in practice. How much information can actually be sent down fibres and what is the best way to do it? Can new optical materials make a difference? How can devices be designed to route information to the right place – such ‘routers’ are just like mail sorting depots for pulses of light. How can fibre optics best be connected into networks so that they work as efficiently as possible – allowing you and everyone else in your street to be watching different movies at the same time, for example, without the film going all jerky? These are all the kinds of questions that fascinate Polina and she has built up an internationally respected team to help her answer them.
Why are optical fibres such a good way to send messages? Well the obvious answer is that you can’t get much faster than light! Well actually you can’t get ANY faster than light. The speed of light is the fastest anything, including information, can travel according to Einstein’s laws. That’s not the end of the story though. Remember the worn out Marathon runner. It turns out that signals being sent down cables do something similar. Well, not actually getting out of breath and dying but they do get weaker the further they travel. That means it gets harder to extract the information at the other end and eventually there is a point where the message is just garbled noise. What’s the solution? Well actually it’s exactly the one the Pony Express came up with. You add what are called ‘repeaters’ every so often. They extract the message from the optical fibre and then send it down the next fibre, but now back at full strength again. One of the benefits of fibre optics is that signals can go much further before they need a repeater. That means the message gets to its destination faster because those repeaters take time extracting and resending the message. That, in turn, leaves scope for improvement. The Pony Express made their ‘repeaters’ faster by giving the rider a horn to alert the stationmaster that they were arriving. He would then have time to get the next horse ready so it could leave the moment the mail was handed over. Researchers like Polina are looking for similar ways to speed up optical repeaters.
You can do more than play with repeaters to speed things up though. You can also bump up the amount of information you carry in one go. In particular you can send lots of messages at the same time over an optical fibre as long as they use different wavelengths. You can think of this as though one person is using a torch with a blue bulb to send a Morse code message using flashes of blue light (say), while someone else is doing the same thing with a red torch and red light. If two people at the other end are wearing tinted sunglasses then depending on the tint they will each see only the red pulses or only the blue ones and so only get the message meant for them. Each new frequency of light used gives a new message that can be sent at the same time.
The tricky bit is not so much in doing that but in working out which people can use which torch at any particular time so their aren’t any clashes, bearing in mind that at any instant messages could be coming from anywhere in the network and trying to go anywhere. If two people try to use the same torch on the same link at the same time it all goes to pot. This is complicated further by the fact that at any time particular links could be very busy, or broken, meaning that different messages may also travel by different routes between the same places, just as you might go a different way to normal when driving if there is a jam. All this, and together with other similar issues, means there are lots of hairy problems to worry about if coming up with a the best possible optical network as Polina is aiming to do.
Polina’s has been highly successful working in this area. She has been made a Fellow of the Royal Academy of Engineering for her work and is also a Royal Society Wolfson Research Merit Award holder. It is only given to respected scientists of outstanding achievement and potential. She has also won the prestigious Patterson Medal awarded for distinguished research in applied physics. It’s important to remember that modern engineering is a team game, though. As she notes she has benefited hugely by having inspiring and supporting mentors, as well as superb students and colleagues. It is her ability to work well with other people that allowed her build a critical mass in her research and so gain all the accolades. All that achieved and she is a mother of two boys to boot. Bringing up children is, of course, a team game too.
Paul Curzon, Queen Mary University of London, Autumn 2011
In our stress-filled world with ever increasing levels of anxiety, it would be nice if technology could sometimes reduce stress rather than just add to it. That is the problem that QMUL’s Christine Farion set out to solve for her PhD. She wanted to do something stylish too, so she created a new kind of bag: a smart bag.
Christine realised that one thing that causes anxiety for a lot of people is forgetting everyday things. It is very common for us to forget keys, train tickets, passports and other everyday things we need for the day. Sometimes it’s just irritating. At other times it can ruin the day. Even when we don’t forget things, we waste time unpacking and repacking bags to make sure we really do have the things we need. Of course, the moment we unpack a bag to check, we increase the chance that something won’t be put back!
Electronic bags
Christine wondered if a smart bag could help. Over the space of several years, she built ten different prototypes using basic electronic kits, allowing her to explore lots of options. Her basic design has coloured lights on the outside of the bag, and a small scanner inside. To use the bag, you attach electronic tags to the things you don’t want to forget. They are like the ones shops use to keep track of stock and prevent shoplifting. Some tags are embedded into things like key fobs, while others can be stuck directly on to an object. Then when you pack your bag, you scan the objects with the reader as you put them in, and the lights show you they are definitely there. The different coloured lights allow you to create clear links – natural mappings – between the lights and the objects. For her own bag, Christine linked the blue light to a blue key fob with her keys, and the yellow light to her yellow hayfever tablet box.
In the wild
One of the strongest things about her work was she tested her bags extensively ‘in the wild’. She gave them to people who used them as part of their normal everyday life, asking them to report to her what did and didn’t work about them. This all fed in to the designs for subsequent bags and allowed her to learn what really mattered to make this kind of bag work for the people using it. One of the key things she discovered was that the technology needed to be completely simple to use. If it wasn’t both obvious how to use and quick and simple to do it wouldn’t be used.
Christine also used the bags herself, keeping a detailed diary of incidents related to the bags and their design. This is called ‘autoethnography’. She even used one bag as her own main bag for a year and a half, building it completely into her life, fixing problems as they arose. She took it to work, shopping, to coffee shops … wherever she went.
Suspicious?
When she had shown people her prototype bags, one of the common worries was that the electronics would look suspicious and be a problem when travelling. She set out to find out, taking her bag on journeys around the country, on trains and even to airports, travelling overseas on several occasions. There were no problems at all.
Fashion matters
As a bag is a personal item we carry around with us, it becomes part of our identity. She found that appropriate styling is, therefore, essential in this kind of wearable technology. There is no point making a smart bag that doesn’t fit the look that people want to carry around. This is a problem with a lot of today’s medical technology, for example. Objects that help with medical conditions: like diabetic monitors or drug pumps and even things as simple and useful as hearing aids or glasses, while ‘solving’ a problem, can lead to stigma if they look ugly. Fashion on the other hand does the opposite. It is all about being cool. Christine showed that by combining design of the technology with an understanding of fashion, her bags were seen as cool. Rather than designing just a single functional smart bag, ideally you need a range of bags, if the idea is to work for everyone.
Now, why don’t I have my glasses with me?
Paul Curzon, Queen Mary University of London, Autumn 2018
It’s the second of three punk gigs in a row for Neurotic and the PVCs, and tonight they’re sounding good. The audience seem to be enjoying it too. All around the room the people are clapping and cheering, and in the middle of the mosh pit the three robots are dancing. They’re jumping up and down in the style of the classic punk pogo, and they’ve been doing it all night whenever they like the music most. Since Neurotic came on the robots can hardly keep still. In fact Neurotic and the PVCs might be the best, most perfect band for these three robots to listen to, since their frontman, Fiddian, made sure they learned to like the same music he does.
Programming punks
It’s a tough task to get a robot to learn what punk music sounds like, but there are lots of hints lurking in our own brains. Inside your brain are billions of connected cells called neurons that can send messages to one another. When and where the messages get sent depends on how strong each connection is, and we forge new connections whenever we learn something.
What the robots’ programmers did was to wire up a network of computerised connections like the ones in a real brain. Then they let the robots sample lots of different kinds of music and told them what it was, like reggae, pop, and of course, Fiddian’s collection of classic punk. That way the connections in the neural network got stronger and stronger – the more music the robots listened to, the easier it got for them to recognise what kind of stuff it was. When they recognised a style they’d been told to look out for, they would dance, firing a cylinder of compressed air to make them jump up and down.
The robots’ first gig
The last step was to tell the robots to go out and enjoy some punk. The programmers turned off the robots’ neural connections to other kinds of music, so no Kylie or Bob Marley would satisfy them. They would only dance to the angry, churning sound of punk guitars. The robots got dressed up in spray-painted leather, studded belts and safety pins, so with their bloblike bodies they looked like extra-tough boxing gloves on sticks. Then the three two-metre tall troublemakers went to their first gig.
Whenever a band begins to play, the robots’ computer system analyses the sound coming from the stage. If the patterns in it look the same as the idea of punk music they’ve learned, the robots begin to dance. If the pattern isn’t quite right, they stand still. For lots of songs they hardly dance at all, which might seem weird since all the bands that are playing the gig call themselves punk bands. Except there are many different styles of punk music, and the robots have been brought up listening to Fiddian’s favourites. The other styles aren’t close enough to the robots’ idea of punk – they’ve developed taste, and it’s the same as Fiddian’s. Which is why the robots go crazy for Neurotic and the PVCs. Fiddian’s songs are influenced by classic punk like the Clash, the Sex Pistols and Siouxsie & the Banshees, which is exactly the music he’s taught the robots to love. As the robots jump wildly up and down, it’s clear that Neurotic and the PVCs now have three tall, tough, computerised superfans.
What happened when a legend of computer science took on the Las Vegas casinos? The answer, surprisingly, was the birth of wearable computing.
There have always been people looking to beat the system, to get that little bit extra of the odds going their way to allow them to clean up at the casino. Over the years maths and technology have been used, from a hidden mechanical arm up your sleeve allowing you to swap cards, to the more cerebral card counting. In the latter, a player remembers a running total of the cards played so they can estimate when high value cards will be dealt. One popular game to try and cheat was Roulette.
A spin of the wheel
Roulette, which comes from the French word ‘little wheel’, involves a dish containing a circular rotating part marked into red and black numbers. A simple version of the game was developed by the French mathematician, Pascal, and it evolved over the centuries to become a popular betting game. The central disc is spun and as it rotates a small ball is thrown into the dish. Players bet on the number that the ball will eventually stop at. The game is based on probability, but like most games there is a house advantage: the probabilities mean that the casino will tend to win more money than it loses.
Gamblers tried to work out betting strategies to win, but the random nature of where the ball stops thwarted them. In fact, the pattern of numbers produced from multiple roulette spins was so random that mathematicians and scientists have used these numbers as a random-number generator. Methods using them are even called Monte Carlo methods after the famous casino town. They are ways to calculate difficult mathematical functions by taking thousands of random samples of their value at different random places.
A mathematical system of betting wasn’t going to work to beat the game, but there was one possible weakness to be exploited: the person who ran the game and threw the ball into the wheel, the croupier.
No more bets please
There is a natural human instinct to spin the wheel and throw the ball in a consistent pattern. Each croupier who has played thousands of games has a slight bias in the speed and force with which they spin the wheel and throw the ball in. If you could just see where the wheel was when the spin started and the ball went in, you could use the short time before betting was suspended to make a rough guess of the area where the ball was more likely to land, giving you an edge. This is called ‘clocking the wheel’, but it requires great skill. You have to watch many games with the same croupier to gain a tiny chance of working out where their ball will go. This isn’t cheating in the same way as physically tampering with the wheel with weights and magnets (which is illegal), it is the skill of the gambler’s observation that gives the edge. Casinos became aware of it, so frequently changed the croupier on each game, so the players couldn’t watch long enough to work out the pattern. But if there was some technological way to work this out quickly perhaps the game could be beaten.
Blackjack and back room
Enter Ed Thorpe, in the 1950s, a graduate student in physics at MIT. Along with his interest in physics he had a love of gambling. Using his access to one of the world’s few room filling IBM computers at the university he was able to run the probabilities in card games and using this wrote a scientific paper on a method to win at Blackjack. This paper brought him to the attention of Claude Shannon, the famous and rather eccentric father of information theory. Shannon loved to invent things: the flame throwing trumpet, the insult machine and other weird and wonderful devices filled the basement workshop of his home. It was there that he and Ed decided to try and take on the casinos at Roulette and built arguably the first wearable computer.
Sounds like a win
The device comprised a pressure switch hidden in a shoe. When the ball was spun and passed a fixed point on the wheel, the wearer pressed the switch. A computer timer, strapped to the wrist, started and was used to track the progress of the ball as it passed around the wheel, using technology in place of human skill to clock the wheel. A series of musical tones told the person using the device where the ball would stop, each tone represented a separate part of the wheel. They tested the device in secret and found that using it gave them a 44% increased chance of correctly predicting the winning numbers. They decided to try it for real … and it worked! However, the fine wires that connected the computer to the earpiece kept breaking, so they gave up after winning only a few dollars. The device, though very simple and for a single purpose, is in the computing museum at MIT. The inventors eventually published the detail in a scientific paper called “The Invention of the First Wearable Computer,” in 1998.
The long arm of the law reaches out
Others followed with similar systems built into shoes, developing more computers and software to help cheat at Blackjack too, but by the mid 1980’s the casino authorities became wise to this way to win, so new laws were introduced to prevent the use of technology to give unfair advantages in casino games. It definitely is now cheating. If you look at the rules for casinos today they specifically exclude the use of mobile phones at the table, for example, just in case your phone is using some clever app to scam the casinos.
From its rather strange beginning, wearable computing has spun out into new areas and applications, and quite where it will go next is anybody’s bet.
Peter W. McOwan, Queen Mary University of London, Autumn 2018
Researchers at MIT and Harvard have new skin in the game when it comes to monitoring people’s bodily health. They have developed a new wearable technology in the form of colour- and shape-changing tattoos. These tattoos work by using bio-sensitive inks, changing colour, fading away or appearing under different coloured illumination, depending on your body chemistry. They could, for example, change their colour, or shape as their parts fade away, depending on your blood glucose levels.
This kind of constantly on, constantly working body monitoring ensures that there is nothing to fall off, get broken or run out of power. That’s important in chronic conditions like diabetes where monitoring and controlling blood glucose levels is crucial to the person’s health. The project, called Dermal Abyss, brings together scientists and artists in a new way to create a data interface on your skin.
There are still lots of questions to answer, like how long will the tattoos last and would people be happy displaying their health status to anyone who catches a glimpse of their body art? How would you feel having your body stats displayed on your tats? It’s a future question for researchers to draw out the answer to.
Peter W. McOwan, Queen Mary University of London, Autumn 2018